下面我将为你提供一个详细的、可运行的 C 语言示例,并分步解释其中的关键点。
(图片来源网络,侵删)
核心原理
要获取网页源码,你需要执行以下步骤:
- 创建 Socket:使用
socket()函数创建一个套接字,这是网络通信的端点。 - 建立连接:使用
connect()函数将你的客户端 Socket 连接到目标 Web 服务器的 Socket(通常是 80 端口,用于 HTTP)。 - 发送 HTTP 请求:通过
send()函数,向服务器发送一个符合 HTTP 协议的 GET 请求,这个请求包含了你想要获取的网页路径(如/index.html)和主机名。 - 接收 HTTP 响应:使用
recv()函数循环从服务器接收数据,服务器会返回一个 HTTP 响应,其中包含响应头和响应体(即网页源码)。 - 解析和提取:你需要对接收到的数据进行解析,找到 HTTP 响应头和响应体之间的分隔符(通常是
\r\n\r\n),然后提取出响应体部分。 - 关闭连接:使用
close()函数关闭 Socket,释放资源。
完整 C 语言代码示例
这个示例会获取 example.com 首页的源码并打印到终端。
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <unistd.h>
#include <sys/socket.h>
#include <netinet/in.h>
#include <netdb.h>
#include <arpa/inet.h>
#define PORT 80
#define BUFFER_SIZE 4096
void error(const char *msg) {
perror(msg);
exit(1);
}
int main(int argc, char *argv[]) {
int sockfd;
struct sockaddr_in serv_addr;
struct hostent *server;
char buffer[BUFFER_SIZE];
char request[BUFFER_SIZE];
// 检查命令行参数
if (argc < 2) {
fprintf(stderr, "Usage: %s <hostname> [path]\n", argv[0]);
fprintf(stderr, "Example: %s example.com /index.html\n", argv[0]);
exit(1);
}
const char *hostname = argv[1];
const char *path = (argc > 2) ? argv[2] : "/"; // 默认路径为根目录 /
// 1. 创建 Socket
// AF_INET 表示 IPv4
// SOCK_STREAM 表示 TCP
// 0 表示使用默认协议 (TCP)
sockfd = socket(AF_INET, SOCK_STREAM, 0);
if (sockfd < 0) {
error("ERROR opening socket");
}
// 2. 获取服务器信息
server = gethostbyname(hostname);
if (server == NULL) {
fprintf(stderr, "ERROR, no such host as %s\n", hostname);
exit(1);
}
// 3. 设置服务器地址结构
memset(&serv_addr, 0, sizeof(serv_addr));
serv_addr.sin_family = AF_INET;
memcpy(&serv_addr.sin_addr.s_addr, server->h_addr, server->h_length);
serv_addr.sin_port = htons(PORT); // 将端口号从主机字节序转换为网络字节序
// 4. 连接到服务器
if (connect(sockfd, (struct sockaddr *)&serv_addr, sizeof(serv_addr)) < 0) {
error("ERROR connecting");
}
printf("Connected to %s on port %d\n", hostname, PORT);
// 5. 构造 HTTP GET 请求
// 请求格式: GET /path HTTP/1.0\r\nHost: hostname\r\n\r\n
snprintf(request, BUFFER_SIZE, "GET %s HTTP/1.0\r\nHost: %s\r\n\r\n", path, hostname);
printf("\n--- Sending HTTP Request ---\n%s\n---------------------------\n", request);
// 6. 发送 HTTP 请求
if (send(sockfd, request, strlen(request), 0) < 0) {
error("ERROR writing to socket");
}
// 7. 接收 HTTP 响应
printf("\n--- Receiving HTTP Response ---\n");
int total_received = 0;
int header_end_found = 0;
char *body_start = NULL;
while (1) {
int n = recv(sockfd, buffer, BUFFER_SIZE - 1, 0);
if (n <= 0) {
break; // 连接关闭或出错
}
buffer[n] = '\0'; // 确保字符串以 null
// 8. 解析响应,找到响应体的开始位置
if (!header_end_found) {
body_start = strstr(buffer, "\r\n\r\n");
if (body_start) {
header_end_found = 1;
// 打印响应头
long header_length = body_start - buffer;
fwrite(buffer, 1, header_length, stdout);
printf("\n--- HTTP Response Body ---\n");
// 打印响应体
body_start += 4; // 跳过 "\r\n\r\n"
printf("%s", body_start);
} else {
// 还没找到头尾,继续打印缓冲区内容(可能是响应头的一部分)
printf("%s", buffer);
}
} else {
// 已经找到响应头,直接打印响应体
printf("%s", buffer);
}
total_received += n;
}
printf("\n--- End of Response ---\n");
printf("Total bytes received: %d\n", total_received);
// 9. 关闭连接
close(sockfd);
return 0;
}
如何编译和运行
-
保存代码:将上面的代码保存为
get_webpage.c。 -
编译:打开终端,使用
gcc进行编译。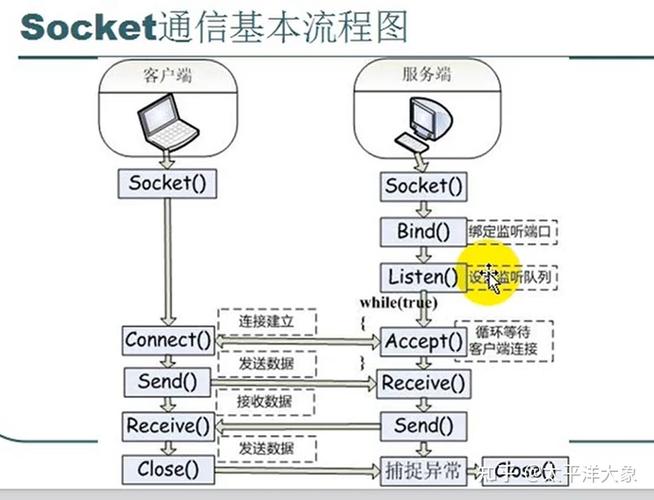 (图片来源网络,侵删)
(图片来源网络,侵删)gcc get_webpage.c -o get_webpage
-
运行:执行编译后的程序,并传入目标主机名和可选的路径。
# 获取 example.com 首页 ./get_webpage example.com # 获取 example.com 的某个特定页面 ./get_webpage example.com /index.html
代码分步详解
-
包含头文件:
sys/socket.h:核心 Socket 函数(socket,connect,send,recv,close)。netinet/in.h:定义了地址结构sockaddr_in和字节序转换函数htons。netdb.h:提供了主机信息查询函数gethostbyname。arpa/inet.h:提供了 IP 地址转换函数。
-
socket():AF_INET:指定使用 IPv4 地址族。SOCK_STREAM:指定使用面向连接的 TCP 协议。- 返回一个文件描述符
sockfd,后续所有操作都通过这个描述符进行。
-
gethostbyname(): (图片来源网络,侵删)
(图片来源网络,侵删)- 这个函数将主机名(如
"example.com")解析为struct hostent结构体,其中包含了服务器的 IP 地址信息。
- 这个函数将主机名(如
-
sockaddr_in结构体:sin_family:必须设置为AF_INET。sin_port:端口号。htons()函数将主机字节序(你的电脑上的顺序)转换为网络字节序(大端序),这是网络通信的标准。sin_addr:服务器的 IP 地址,我们使用memcpy将gethostbyname得到的地址复制过来。
-
connect():尝试与服务器建立 TCP 连接,如果成功,就可以开始双向数据传输了。
-
构造 HTTP 请求:
snprintf用于格式化字符串,创建一个合法的 HTTP GET 请求。GET / HTTP/1.0\r\n:请求方法、路径和 HTTP 版本。HTTP/1.0是一个较简单的版本,连接在请求响应后会自动关闭。Host: example.com\r\n:这是必须的,HTTP/1.1 协议要求,用于虚拟主机场景,告诉服务器你要访问的是哪个域名。\r\n\r\n:一个空行,标志着 HTTP 请求头的结束。
-
send()和recv():send()将构造好的 HTTP 请求发送到服务器。recv()是一个阻塞函数,它会等待接收数据,我们用一个while循环来持续接收,直到服务器关闭连接(recv返回 0)或发生错误(返回 -1)。
-
解析响应:
- HTTP 响应由 响应头 和 响应体 组成,它们之间用
\r\n\r\n分隔。 strstr(buffer, "\r\n\r\n")函数用于在接收到的数据块中查找这个分隔符。- 第一次找到分隔符时:
- 打印分隔符之前的所有内容(即响应头)。
- 计算响应体的起始位置。
- 之后:直接打印缓冲区中的所有内容,因为它们都属于响应体。
- HTTP 响应由 响应头 和 响应体 组成,它们之间用
-
close():关闭 Socket,释放系统资源,这是一个良好的编程习惯。
重要注意事项
- HTTP/1.1 vs HTTP/1.0:示例中使用的是
HTTP/1.0,因为它在响应结束后会自动关闭连接,简化了客户端的逻辑,如果使用HTTP/1.1,服务器可能会使用 "Keep-Alive" 机制保持连接,你需要额外处理连接的关闭逻辑(根据Content-Length判断响应是否接收完整,或者等待服务器主动关闭连接)。 - 错误处理:代码中使用了简单的
perror和exit来处理错误,在实际的生产环境中,你需要更健壮的错误处理和恢复机制。 - HTTPS:这个例子只能获取 HTTP 协议的内容,如果要获取 HTTPS (加密) 内容,过程会复杂得多,需要实现 SSL/TLS 握手过程,通常使用 OpenSSL 这样的库来完成。
- 缓冲区大小:
BUFFER_SIZE定义了每次接收的最大字节数,如果网页很大,recv会被多次调用,循环处理是必要的。


