DedeCMS 5.7 采集功能详细教程
DedeCMS 的采集是其核心功能之一,虽然界面看起来有些复杂,但只要理解了基本流程,就能轻松上手。
(图片来源网络,侵删)
采集前的准备工作(非常重要!)
在开始采集之前,请务必做好以下准备工作,这能避免很多后续问题。
-
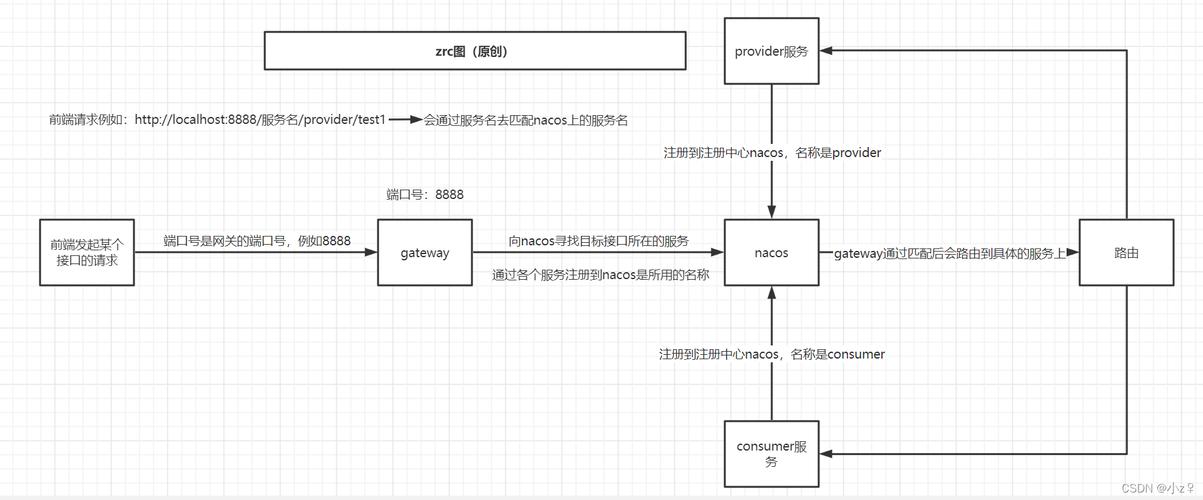
明确采集目标:
- 目标网站: 确定你要采集哪个网站,确保该网站允许采集(遵守其
robots.txt协议和版权声明),否则可能涉及法律风险。 - 目标栏目: 确定采集到的内容要发布到你网站的哪个栏目。这个栏目必须是“最终栏目”,不能是带有子栏目的父栏目,如果需要,请先在后台创建好目标栏目。
- 目标网站: 确定你要采集哪个网站,确保该网站允许采集(遵守其
-
分析目标网站(关键步骤):
- 列表页: 找到目标网站包含所有文章链接的页面,通常是“首页”、“列表页”或“分类页”。
https://example.com/news/list_1.html - 文章页: 点击列表页中的一篇文章,进入其内容页面。
https://example.com/news/a/2025/12345.html - 内容结构: 仔细观察文章页的 HTML 结构,找出你需要采集的字段(如标题、内容、发布时间、来源、作者等)对应的 HTML 标签和
class或id名称。
如何分析?
 (图片来源网络,侵删)
(图片来源网络,侵删)- 浏览器开发者工具: 在 Chrome 或 Firefox 浏览器中,打开文章页,在内容上点击鼠标右键,选择“检查”或“检查元素”,这会打开开发者工具,高亮显示该内容对应的 HTML 代码,你需要找到包裹这些内容的
<div>或<span>等标签,并记下它们的class或id。- 标题可能在
<h1 class="article-title">...</h1>中。 - 内容可能在
<div class="article-content">...</div>中。 - 发布时间可能在
<span class="post-time">...</span>中。
- 标题可能在
- 列表页: 找到目标网站包含所有文章链接的页面,通常是“首页”、“列表页”或“分类页”。
-
配置网站环境:
- 开启
allow_url_fopen: 确保你的 PHP 环境开启了allow_url_fopen选项,这是 PHP 用来获取远程网页内容的基础,通常虚拟主机都已开启。 php.ini文件中检查:allow_url_fopen = On
- 开启
采集详细步骤(以采集文章为例)
登录你的 DedeCMS 后台,路径通常是:你的域名/dede/
第一步:创建新采集任务
- 在后台左侧菜单栏,找到
采集->采集侠或一键采集(不同版本名称可能略有差异,但功能类似,我们以传统的“采集侠”为例进行讲解)。 - 点击 “增加新采集” 或 “新建任务” 按钮。
第二步:配置基本任务信息
- 任务名称: 给你的采集任务起一个容易识别的名字,XX新闻网采集”。
- 目标网址: 填入你之前分析好的 列表页 URL。
- 高级用法: 如果列表页有分页,
list_1_1.html,list_1_2.html,你可以使用通配符 来表示。https://example.com/news/list_1_*.html,这样就能一次性采集多个分页的文章。
- 高级用法: 如果列表页有分页,
- 保存目录: 选择采集到的文章图片、附件等要保存到你网站的哪个目录,通常使用默认即可。
- 作者: 可以设置为固定的作者名,或者选择“从来源获取”。
- 来源: 可以设置为固定的来源名,或者选择“从来源获取”。
- 可以设置为固定的关键词,或者留空让系统自动从标题提取。
- 简介: 可以选择“截取正文开头”、“从来源获取”或留空。
第三步:配置列表规则(最关键的一步)
这一步的目的是告诉 DedeCMS 如何从列表页中找到所有文章的真实链接。
- 列表开始标记: 在右侧的“测试获取网页内容”框中,你会看到列表页的源代码,你需要找到列表区域开始的 HTML 标签。
- 如果所有文章链接都在一个
<div class="news-list">里面,那么就在这里填入<div class="news-list">。
- 如果所有文章链接都在一个
- 列表结束标记: 同理,找到列表区域结束的标签。
</div>。 - 列表间隔符: 通常留空,如果列表项之间有特定的分隔符(如
<hr>),可以在这里填写。 - 链接地址: 这是重中之重,你需要告诉 DedeCMS 如何从每个列表项中提取文章的 URL。
- 在源代码中找到一条文章链接对应的 HTML,
<a href="/news/a/2025/12345.html" title="文章标题">...</a>。 - 选择匹配方式:
- 链接式: 这是最常用的,直接复制上面的
href属性值,但要保留通配符 。/news/a/2025/*.html。 - 标签式: 如果链接是
<li class="item"><a ...>...</a></li>,你可以用<li class="item">作为开始,</li>作为结束,然后在里面用链接地址规则提取。
- 链接式: 这是最常用的,直接复制上面的
- 在源代码中找到一条文章链接对应的 HTML,
- 分页: 如果列表页有分页导航,可以在这里配置分页规则,实现自动翻页采集。
- 分页开始/结束标记: 找到分页导航的容器。
- 分页链接地址: 找到“下一页”按钮的链接,提取其 URL 模式。
第四步:配置内容规则
这一步是告诉 DedeCMS 如何从每一篇文章页中提取具体内容。
- 页网址: 通常会自动从列表规则中继承,无需修改。
- 内容链接: 填入你分析到的标题标签。
<h1 class="article-title">...</h1>。 - 过滤代码: 可以在这里写一些正则表达式来过滤标题中不需要的字符(如广告、特殊符号)。
- 内容链接: 填入你分析到的标题标签。
- 发布时间:
- 内容链接: 填入你分析到的时间标签。
<span class="post-time">...</span>。 - 时间格式: 非常重要! 必须和目标网站的时间格式完全一致,常见的格式有:
YYYY-MM-DD HH:II:SS(2025-10-27 15:30:00)YYYY/MM/DD HH:II:SSMM-DD-YYYY HH:II:SS
- 内容链接: 填入你分析到的时间标签。
- 内容正文:
- 内容链接: 填入你分析到的正文内容区域的标签。
<div class="article-content">...</div>。 - 处理方式:
- 保留HTML: 会保留原文的排版、图片、链接等。
- 只保留文字: 只提取纯文本,去除所有 HTML 标签。
- 去除特定标签: 可以输入要去除的标签名,如
script,iframe,用来过滤广告代码。
- 内容链接: 填入你分析到的正文内容区域的标签。
- 作者: 填入作者对应的标签。
- 来源: 填入来源对应的标签。
- 图片/附件处理:
- 本地保存: 勾选此项,会下载文章中的图片到你的网站服务器,并自动替换链接为本地路径,这是推荐的做法,可以防止对方网站图片失效或盗链。
- 目录: 设置图片保存的子目录。
- 替换远程地址: 可以设置将远程图片地址替换为本地地址。
- 分页处理:
- 如果目标文章是分页显示的(如“下一页”),你需要在这里配置规则,让 DedeCMS 自动抓取所有分页的内容并合并成一篇完整的文章。
- 开始/结束标记: 找到分页按钮的容器。
- 下一页链接地址: 找到“下一页”按钮的链接模式。
第五步:选择目标栏目和测试采集
- 选择栏目: 在任务配置的下方,找到 “选择栏目” 按钮,点击并选择你之前准备好的 最终栏目。
- 保存任务: 所有规则填写完毕后,点击 “保存” 或 “下一步”。
- 测试采集:
- 在任务列表中找到你刚刚创建的任务,点击后面的 “选择” 或 “开始采集”。
- 系统会先列出从列表页中找到的所有文章链接,让你确认。
- 确认无误后,点击 “开始采集”,系统会逐个打开文章页,按照你设定的规则抓取内容。
- 你可以在采集过程中查看状态,直到采集完成。
采集后的处理与技巧
- 内容审核: 采集完成后,请务必去对应栏目检查一下发布的内容,DedeCMS 采集默认是“审核通过”的,但有时会因为规则匹配问题导致内容错乱、图片丢失等,建议先采集少量内容测试,确认无误后再批量采集。
- 批量管理: 在后台 ->
批量维护中,可以对采集到的文章进行批量操作,如修改状态、移动栏目、删除等。 - 利用“采集侠”高级功能:
- 自定义采集: 可以更灵活地编写规则,甚至采集非文章内容(如下载软件、商品等)。
- 任务循环: 设置任务定时自动运行,实现每天自动更新网站内容。
- 遇到问题怎么办?
- 采集不到内容: 90% 的问题是 列表规则 或 内容规则 的
class/id写错了,回到第二步和第三步,用浏览器开发者工具重新仔细检查目标网站的 HTML 结构。 - 内容乱码: 检查目标网站的编码格式(通常是 UTF-8 或 GBK),并确保你的网站系统设置与之匹配。
- 图片无法保存: 检查目录权限是否正确(确保 web 服务器有写入权限),或检查“本地保存”选项是否勾选。
- 采集不到内容: 90% 的问题是 列表规则 或 内容规则 的
重要注意事项与风险提示
- 版权问题: 这是最重要的一点! 采集他人内容可能侵犯对方的著作权,请务必遵守目标网站的
robots.txt协议和版权声明,建议仅用于学习研究,或采集明确声明可以转载的内容,并在转载时注明来源和作者。 - 网站安全: 不要从不明或存在安全风险的网站采集,以免你的网站被植入恶意代码。
- 服务器负载: 大量、高频的采集会给你的服务器带来较大压力,可能导致网站卡顿甚至被主机商警告,请合理设置采集频率和数量。
- 搜索引擎优化: 大量重复内容对网站的 SEO(搜索引擎优化)非常不利,搜索引擎会惩罚那些内容高度同质化的网站,采集来的内容最好进行二次编辑和原创化处理,再进行发布。
希望这份详细的教程能帮助你成功掌握 DedeCMS 5.7 的采集功能!祝你使用愉快!


