网页信息提取完整模板
这个模板使用 Python 语言,因为它在爬虫领域拥有最成熟、最强大的库(如 requests, BeautifulSoup, lxml)。

(图片来源网络,侵删)
第1步:准备工作(安装必要的库)
在开始之前,你需要确保已经安装了 Python,然后通过 pip 安装以下库:
# 用于发送 HTTP 请求,获取网页内容 pip install requests # 用于解析 HTML/XML 文档,提取信息 pip install beautifulsoup4 # (可选) 一个更快的解析器,比 Python 自带的 html.parser 更快 pip install lxml
第2步:模板代码
这是一个功能完整的 Python 脚本模板,你可以根据你的目标网页修改其中的 URL、选择器 和 数据结构。
# -*- coding: utf-8 -*-
import requests
from bs4 import BeautifulSoup
import time
import csv
# ==============================================================================
# 1. 配置部分 - 在这里修改你的目标
# ==============================================================================
# 目标网页的 URL
TARGET_URL = "https://quotes.toscrape.com/" # 以一个著名的名言网站为例
# 你要提取的数据的字段名称(这将作为 CSV 文件的表头)
# ['quote_text', 'author', 'tags']
CSV_HEADER = ['quote_text', 'author', 'tags']
# 存储数据的文件名
OUTPUT_CSV_FILE = 'quotes_data.csv'
# 设置请求头,模拟浏览器访问,避免被反爬
HEADERS = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36'
}
# ==============================================================================
# 2. 核心提取函数 - 在这里定义你的提取逻辑
# ==============================================================================
def extract_data_from_page(url):
"""
发送请求并解析单个页面,提取所需信息。
"""
try:
# 1. 发送 HTTP 请求
response = requests.get(url, headers=HEADERS, timeout=10)
# 2. 检查请求是否成功 (状态码 200)
response.raise_for_status()
# 3. 使用 BeautifulSoup 解析 HTML
# 'lxml' 是一个更快的解析器,如果安装了,推荐使用
soup = BeautifulSoup(response.text, 'lxml')
# 4. 使用 CSS 选择器或 XPath 定位元素
# --- 这是关键步骤,需要你用浏览器开发者工具分析网页结构 ---
# 在 quotes.toscrape.com 中,每条名言都在一个 class="quote" 的 div 中
quote_containers = soup.find_all('div', class_='quote')
extracted_items = []
# 5. 遍历所有找到的容器,提取具体信息
for container in quote_containers:
# 提取名言文本 (在 class="text" 的 span 标签中)
quote_text = container.find('span', class_='text').text.strip()
# 提取作者 (在 class="author" 的小标签中)
author = container.find('small', class_='author').text.strip()
# 提取标签 (在 class="tags" 的 div 中,所有的 a 标签)
tags_container = container.find('div', class_='tags')
tags = [tag.text.strip() for tag in tags_container.find_all('a')] # 使用列表推导式
# 将提取的数据存入一个字典
data_item = {
'quote_text': quote_text,
'author': author,
'tags': ', '.join(tags) # 将标签列表用逗号连接成字符串
}
extracted_items.append(data_item)
return extracted_items
except requests.exceptions.RequestException as e:
print(f"请求 {url} 时发生错误: {e}")
return None
# ==============================================================================
# 3. 主函数 - 控制流程
# ==============================================================================
def main():
"""
主函数,协调整个提取和保存过程。
"""
print(f"开始从 {TARGET_URL} 提取数据...")
# 调用提取函数
all_data = extract_data_from_page(TARGET_URL)
if all_data:
print(f"成功提取 {len(all_data)} 条数据。")
# 将数据保存到 CSV 文件
try:
with open(OUTPUT_CSV_FILE, 'w', newline='', encoding='utf-8-sig') as f:
# 使用 DictWriter 写入字典数据
writer = csv.DictWriter(f, fieldnames=CSV_HEADER)
# 写入表头
writer.writeheader()
# 写入数据行
writer.writerows(all_data)
print(f"数据已成功保存到 {OUTPUT_CSV_FILE}")
except IOError as e:
print(f"保存文件时发生错误: {e}")
else:
print("未能提取到任何数据。")
# ==============================================================================
# 4. 执行入口
# ==============================================================================
if __name__ == '__main__':
main()
第3步:如何使用这个模板(分步指南)
核心难点:如何找到正确的“选择器”?
这是整个模板中最关键的一步,你需要使用浏览器的开发者工具来帮你。
(图片来源网络,侵删)
- 打开目标网页,
https://quotes.toscrape.com/。 - 右键点击你想要提取的信息(比如一条名言),选择“检查”(Inspect)。
- 浏览器会自动打开开发者工具,并高亮显示对应的那段 HTML 代码。
- 分析代码结构:
- 你会发现名言文本在一个
<span class="text">...</span>标签里。 - 作者在一个
<small class="author">...</small>标签里。 - 所有名言都在一个
<div class="quote">...</div>的容器里。
- 你会发现名言文本在一个
根据分析结果,修改模板中的选择器:
soup.find_all('div', class_='quote'): 这个选择器对应了“找到所有名言的容器”。find_all会返回一个列表,因为网页上有多条名言。container.find('span', class_='text'): 在找到的单个容器(container)里,再寻找名言文本。find只返回第一个匹配的元素。.text: 获取标签内部的纯文本内容。.strip(): 去除文本前后的空白字符(如换行符、空格)。
修改模板以适应你的新目标:
假设你要提取一个新闻网站的文章列表,包含“标题”、“链接”和“发布时间”。
-
修改
CSV_HEADER: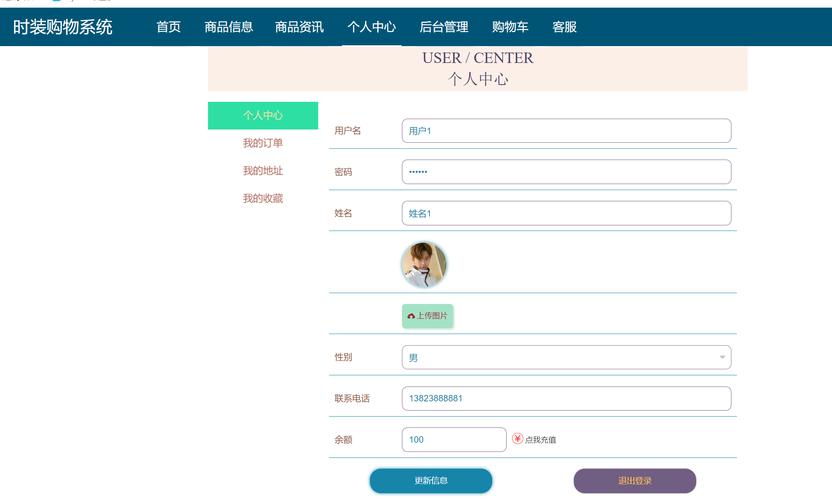 (图片来源网络,侵删)
(图片来源网络,侵删)CSV_HEADER = ['title', 'link', 'publish_time']
-
修改
extract_data_from_page函数中的选择器:# 假设每篇文章在 class="article-item" 的 div 中 article_containers = soup.find_all('div', class_='article-item') for container in article_containers: # 提取标题 (在 class="title" 的 h2 标签中) title = container.find('h2', class_='title').text.strip() # 提取链接 (在 class="title" 的 h2 标签里的 a 标签的 href 属性) link = container.find('h2', class_='title').find('a')['href'] # 如果链接是相对路径,可能需要拼接 URL # link = requests.compat.urljoin(url, link) # 提取时间 (在 class="time" 的 span 标签中) publish_time = container.find('span', class_='time').text.strip() data_item = { 'title': title, 'link': link, 'publish_time': publish_time } extracted_items.append(data_item)
第4步:进阶与注意事项
-
处理 JavaScript 渲染的网页:
- 有些网站(如单页应用 SPA)内容是通过 JavaScript 动态加载的,
requests只能获取到初始的、不含动态内容的 HTML。 - 解决方案:使用 Selenium 或 Playwright 等自动化工具,它们可以模拟一个真实的浏览器,等待 JavaScript 渲染完成后再获取页面源码。
- 模板调整:你需要用 Selenium 的 WebDriver 打开页面,然后获取
page_source,再传给 BeautifulSoup。
# Selenium + BeautifulSoup 的简化示例 from selenium import webdriver from bs4 import BeautifulSoup driver = webdriver.Chrome() # 需要安装 ChromeDriver driver.get(TARGET_URL) # 等待 JS 渲染,例如等待某个元素出现 # time.sleep(5) # 简单粗暴的等待 soup = BeautifulSoup(driver.page_source, 'lxml') # ... 后续步骤与模板相同 ... driver.quit()
- 有些网站(如单页应用 SPA)内容是通过 JavaScript 动态加载的,
-
反爬虫机制:
- User-Agent: 模板中已包含,这是最基本的。
- IP 封禁: 如果频繁请求,你的 IP 可能被禁止访问,可以使用 代理 IP 池。
- 验证码: 网站会弹出验证码要求你证明是真人,这需要更复杂的解决方案,如集成打码平台。
- 请求频率: 在两次请求之间加入
time.sleep(1)或更长的随机延迟,模拟人类浏览行为,模板中已包含import time。
-
数据存储:
- CSV: 适合结构化的表格数据,易于用 Excel 等软件打开。
- JSON: 更灵活,可以存储嵌套结构的数据,是 API 交互的常用格式。
- 数据库: 如果数据量巨大,或需要频繁查询,应存入 MySQL, PostgreSQL, MongoDB 等数据库。
-
遵守
robots.txt和网站条款:- 在爬取任何网站前,请务必检查其根目录下的
robots.txt文件(https://example.com/robots.txt),它会告诉你哪些页面可以爬,哪些不可以。 - 不要对服务器造成过大压力,合理设置请求频率。
- 在爬取任何网站前,请务必检查其根目录下的
这个模板为你提供了一个坚实的基础,掌握了如何分析网页结构和修改选择器,你就可以应对绝大多数静态网页的信息提取任务。


