Xunsearch 教程:从入门到精通
目录
- 什么是 Xunsearch?
- 核心特点
- 适用场景
- 快速入门:第一个搜索应用
- 环境准备
- 安装 Xunsearch
- 第一步:定义索引结构 (
ini文件) - 第二步:创建索引数据 (
PHP代码) - 第三步:执行搜索 (
PHP代码) - 运行与验证
- 核心概念详解
- 索引:什么是索引?为什么需要它?
- 字段:
id,title,body等字段的类型和作用 - 字段类型:
title,body,numeric,date,id,string的区别 - 索引与搜索的一致性:为什么添加数据后不能立刻搜索到?
- API 核心类与方法详解
XS: 入口类,管理整个生命周期XSIndex: 索引操作类 (增删改)XSSearch: 搜索操作类 (查询)XSDocument: 数据文档类
- 进阶功能与实战技巧
- 数据更新与删除
- 高级搜索语法:, , ,
field:, 通配符 - 排序与分页
- 权重/相关性控制
- 模糊搜索与拼音搜索
- 增量索引与重建索引
- 中文分词与自定义词典
- 常见问题与解决方案 (FAQ)
- Q: 添加数据后为什么搜索不到?
- Q: 如何处理大数据量的索引?
- Q: 搜索结果不准确怎么办?
- Q: 如何在项目中集成?
- 总结与资源
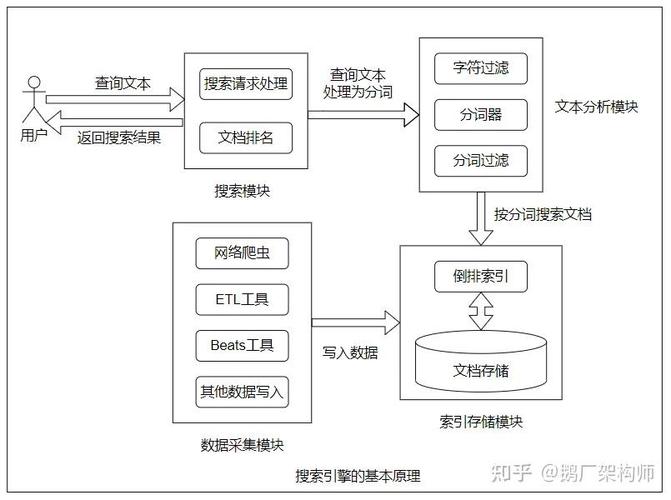
什么是 Xunsearch?
Xunsearch (原名 Sphinx) 是一个功能强大、简单易用的专业全文检索引擎,它由 C++ 语言开发,为 PHP 应用提供了量身定制的 API。
核心特点
- 高性能:基于 C++,索引和搜索速度极快,适合海量数据。
- 功能丰富:支持全文检索、模糊搜索、拼音搜索、高亮显示、字段排序、地理位置搜索等。
- 简单易用:提供了清晰的
ini配置文件和简洁的 PHP API,学习成本低。 - 稳定可靠:经过大量商业项目验证,稳定性和可靠性高。
- 开源免费:遵循 BSD 协议,可以免费用于商业项目。
适用场景
- 网站站内搜索:电商、论坛、博客、新闻门户等。
- 日志数据分析:快速检索和分析服务器日志、应用日志。
- 数据挖掘与分析:从大量非结构化文本中提取有价值信息。
- 任何需要快速、精准文本检索的应用。
快速入门:第一个搜索应用
我们将创建一个简单的文章搜索功能,包含标题和内容。
环境准备
- PHP: 版本 >= 5.2.0 (推荐 7.0+)
- 操作系统: Linux, macOS, Windows
- Web 服务器: Apache, Nginx (可选,CLI 模式即可运行)
安装 Xunsearch
- 下载:从 Xunsearch 官网 下载最新版的稳定版。
- 解压:将下载的压缩包解压到你的项目目录或任意位置,
/usr/local/xunsearch。 - 安装依赖:Xunsearch 依赖一些第三方库(如
libiconv,libevent,libmysqlclient),请根据你的系统运行其自带的sh setup.sh脚本,它会自动检测并提示你如何安装依赖。 - 环境变量 (推荐):为了方便使用,可以将 Xunsearch 的
bin目录添加到系统PATH环境变量中。- Linux/macOS:
export PATH=$PATH:/path/to/xunsearch/bin - Windows: 将
bin目录路径添加到系统环境变量的Path中。
- Linux/macOS:
第一步:定义索引结构 (ini 文件)
这是 Xunsearch 的核心配置,告诉引擎如何处理你的数据。
在你的项目目录下创建一个 ini 文件,blog.ini:
; blog.ini - 博客文章搜索索引定义 project.name = blog_project ; 项目名称,用于生成索引文件前缀 ; 字段定义 [type]字段,用于标题,类型为标题,会进行分词和索引,权重较高= title ; content 字段,用于文章内容,类型为正文,会进行分词和索引 content = body ; id 字段,用于唯一标识,类型为ID,必须是整数且唯一 id = id ; author 字段,用于作者,类型为字符串,不进行分词,但可搜索和排序 author = string ; post_time 字段,用于发布时间,类型为数值,可用于排序和范围过滤 post_time = numeric ; url 字段,用于文章链接,类型为字符串,不进行分词,但可搜索和排序 url = string [search] ; 默认搜索的字段,可以多个,用逗号隔开 default_field = title, content
第二步:创建索引数据 (PHP 代码)
现在我们写一个 PHP 脚本来添加一些示例数据到索引中,创建文件 indexer.php:
<?php
// 引入 Xunsearch SDK 的核心文件
// 请根据你的实际安装路径修改
require_once '/usr/local/xunsearch/sdk/php/lib/XS.php';
try {
// 创建一个 XS 对象,ini 文件路径相对于当前脚本或绝对路径
$xs = new XS('blog.ini');
// 获取索引对象
$index = $xs->index;
// 清空旧索引(可选,第一次运行可以注释掉)
// $index->clean();
// 创建一个文档对象
$doc = new XSDocument();
// 添加数据到文档
// 注意:字段名必须和 ini 文件中定义的一致
$doc->setField('id', 1);
$doc->setField('title', 'Xunsearch 入门教程');
$doc->setField('content', 'Xunsearch 是一个强大的全文检索引擎,本教程将带你快速入门。');
$doc->setField('author', '张三');
$doc->setField('post_time', time() - 86400); // 一天前
$doc->setField('url', '/article/1');
// 将文档添加到索引
$index->add($doc);
// 添加第二篇文章
$doc2 = new XSDocument();
$doc2->setField('id', 2);
$doc2->setField('title', 'PHP 开发最佳实践');
$doc2->setField('content', '在 PHP 开发中,遵循一些最佳实践可以让你的代码更健壮、更高效,使用命名空间、依赖注入等。');
$doc2->setField('author', '李四');
$doc2->setField('post_time', time() - 43200); // 12小时前
$doc2->setField('url', '/article/2');
$index->add($doc2);
echo "索引添加成功!\n";
} catch (Exception $e) {
echo "错误: " . $e->getMessage() . "\n";
}
运行脚本:
在命令行中执行 php indexer.php,如果一切正常,你会看到 "索引添加成功!",在你的项目目录下会生成一些 .ini, .dat, .idx 等文件,这就是索引数据。
第三步:执行搜索 (PHP 代码)
我们创建一个搜索页面,创建文件 search.php:
<?php
require_once '/usr/local/xunsearch/sdk/php/lib/XS.php';
// 获取搜索关键词,从 GET 参数 'q' 中获取
$keyword = isset($_GET['q']) ? trim($_GET['q']) : '';
if ($keyword) {
try {
// 创建一个 XS 对象
$xs = new XS('blog.ini');
// 获取搜索对象
$search = $xs->search;
// 执行搜索
// search() 方法返回一个 XSSearchResult 对象
$result = $search->search($keyword);
echo "搜索关键词: " . htmlspecialchars($keyword) . "<br>";
echo "找到 " . $result->count . " 条结果 (耗时 " . $result->took . " 毫秒)<br><hr>";
// 遍历结果
foreach ($result as $doc) {
// $doc 是一个 XSDocument 对象
echo "<h3><a href='" . htmlspecialchars($doc->url) . "'>" . htmlspecialchars($doc->title) . "</a></h3>";
echo "<p>作者: " . htmlspecialchars($doc->author) . " | 发布时间: " . date('Y-m-d H:i:s', $doc->post_time) . "</p>";
echo "<p>" . htmlspecialchars($doc->content) . "</p>";
echo "<hr>";
}
} catch (Exception $e) {
echo "搜索错误: " . $e->getMessage() . "<br>";
}
} else {
echo "请输入搜索关键词。<br>";
echo "<form action='' method='get'>"
. "<input type='text' name='q' placeholder='输入关键词...'>"
. "<input type='submit' value='搜索'>"
. "</form>";
}
运行搜索:
通过浏览器访问 http://localhost/your_project/search.php?q=php,你应该能看到与 "php" 相关的搜索结果。
核心概念详解
索引
索引可以理解为书籍的目录,Xunsearch 会对你的文本数据进行预处理,建立一种可以快速查找的数据结构(如倒排索引),没有索引,搜索就需要遍历所有数据(全表扫描),效率极低。建立索引是搜索的前提。
字段
字段是数据的基本单元,对应你数据表中的列或文档中的某个部分,在 ini 文件中定义字段时,需要指定其类型。
字段类型 (标题): 最常用,会进行分词,支持模糊搜索,搜索权重高,适用于标题、关键词等简短文本。
body(正文): 最常用,会进行分词,支持模糊搜索,但权重低于title,适用于文章内容、描述等长文本。id(ID): 唯一标识,必须是整数,且值必须唯一,用于数据的精确更新和删除。numeric(数值): 整数或浮点数,可用于排序和范围过滤(如price:100-200),但不支持全文搜索。date(日期): Unix 时间戳格式,可用于排序和范围过滤(如post_time:>1672531200),不支持全文搜索。string(字符串): 不进行分词,可以搜索和排序,但只能做精确匹配或前缀匹配,适用于作者、标签、URL 等。bool(布尔):true或false,可用于过滤,不支持搜索。
索引与搜索的一致性
当你添加或删除数据时,这些变更会先写入一个日志文件,你需要通过 index->flush() 或 index->reindex() 等操作,将变更真正合并到主索引文件中,这个过程称为 提交。
index->add()/index->update()/index->del()只是操作日志。index->flush()将日志合并到主索引,搜索结果会立即更新。index->reindex()是重建索引,更彻底,但耗时更长。
在 indexer.php 的例子中,我们没有显式调用 flush(),因为 Xunsearch 的 XSIndex 对象在脚本执行结束时会自动提交,但在后台任务或 Web 环境中,最好显式调用。
API 核心类与方法详解
XS: 入口类
$xs = new XS('ini_file_path'); // 初始化,传入 ini 文件路径
$index = $xs->index; // 获取索引操作对象
$search = $xs->search; // 获取搜索操作对象
XSIndex: 索引操作类
$index = $xs->index;
// 添加文档
$doc = new XSDocument();
$doc->setField('id', 123);
$doc->setField('title', '新文章');
$index->add($doc);
// 更新文档 (本质是删除再添加)
// 必须有 id 字段
$doc->setField('id', 123);
$doc->setField('title', '更新后的标题');
$index->update($doc);
// 删除文档
$index->del(123); // 根据 ID 删除
// 提交日志到主索引
$index->flush();
// 清空所有索引
$index->clean();
// 重建索引 (先清空再重建)
$index->reindex();
XSSearch: 搜索操作类
$search = $xs->search;
// 设置搜索关键词
$search->setQuery('php教程'); // 最简单的搜索
// 高级搜索语法
$search->setQuery('+标题 -"全文检索" author:张三');
// 设置排序
$search->setSort('post_time', false); // 按发布时间倒序排列,false表示降序,true表示升序
// 设置分页
$search->setLimit(10, 20); // 每页10条,从第21条开始 (page 3)
// 执行搜索
$result = $search->search();
// 获取搜索结果
$total = $result->count; // 总结果数
$docs = $result->docs; // 结果文档数组 (XSDocument 对象)
$took = $result->took; // 搜索耗时(毫秒)
XSDocument: 数据文档类
作为数据载体,用于在索引操作时传递数据。
$doc = new XSDocument();
// 设置字段值
$doc->setField('id', 1);
$doc->setField('title', '我的文档');
// 从数组创建
$data = ['id' => 1, 'title' => '我的文档'];
$doc = new XSDocument($data);
// 获取字段值
$id = $doc->id;
$title = $doc->title;
进阶功能与实战技巧
数据更新与删除
如上所述,更新和删除都依赖于 id 字段,确保你的数据有唯一的 id。
高级搜索语法
Xunsearch 支持类 Google 的搜索语法:
- (与):
关键词1 关键词2或+关键词1 +关键词2,同时包含两个词。 - (非):
关键词1 -关键词2,包含关键词1但不包含关键词2。 - (短语):
"全文检索",精确匹配这个短语。 field:(字段):author:张三,只在author字段中搜索。- (通配符):
php*可以匹配 "php", "php教程" 等。*教程可以匹配 "入门教程", "高级教程" 等。注意:通配符不能出现在词的开头。
排序与分页
// 综合排序 + 自定义排序 // 先按相关性排序(默认),相关性相同时,按发布时间倒序 $search->setMultiSort(['@rank' => 'desc', 'post_time' => 'desc']); // 分页 $page = isset($_GET['page']) ? (int)$_GET['page'] : 1; $pageSize = 10; $offset = ($page - 1) * $pageSize; $search->setLimit($pageSize, $offset);
权重/相关性控制
在 ini 文件中,可以通过 weight 属性设置字段的默认权重。
[type]= title; weight=80 content = body; weight=60 author = string; weight=40
在搜索时,也可以动态调整权重:
// 让 'title' 字段的权重在本次搜索中变为 100
$search->addWeight('title', 100);
模糊搜索与拼音搜索
这需要在 ini 文件中开启支持。
[search] ; 开启模糊搜索,fuzzy=1 表示开启 fuzzy = 1 ; 开启拼音搜索,pinyin=1 表示开启 pinyin = 1
开启后,搜索 php 也能匹配到 PHP,搜索 ruanjian 也能匹配到 软件。
增量索引与重建索引
- 重建索引 (
reindex):适用于数据量不大或索引损坏的情况,它会清空所有旧索引,然后重新从数据源(如 MySQL)构建一遍。非常耗时。 - 增量索引:适用于数据量大且频繁更新的场景,核心思想是:
- 定时任务(如 crontab)运行一个脚本,从数据库中获取自上次索引以来新增或修改的数据。
- 使用
index->add()和index->update()将这些数据添加到索引日志。 - 运行
index->flush()将日志合并到主索引。
中文分词与自定义词典
Xunsearch 默认使用 SCWS (Simple Chinese Word System) 进行中文分词。
- 自定义词典:你可以添加自己的词语,让分词更准确。
- 在
ini文件中指定词典路径:[general] dict = /path/to/your/dict.txt
- 创建
dict.txt文件,格式为词语 权重 词性(词性和权重可选)。Xunsearch 100 n 全文检索 100 n
- 在
- 停用词词典:过滤掉无意义的词(如“的”、“是”、“在”)。
[general] stop = /path/to/your/stop.txt
创建
stop.txt,每行一个停用词。
常见问题与解决方案 (FAQ)
Q: 添加数据后为什么搜索不到?
A: 这是最常见的问题,原因通常是:
- 未提交索引:忘记调用
$index->flush(),在 CLI 脚本中,脚本结束时会自动提交,但在 Web 环境或长时间脚本中必须手动调用。 - 搜索的字段类型不支持全文搜索:比如你在
string或numeric字段中搜索,它们不会被分词和索引。 - 拼写错误:检查
ini文件中的字段名和 PHP 代码中的字段名是否一致。
Q: 如何处理大数据量的索引?
A:
- 使用增量索引:避免频繁
reindex。 - 分批处理:在添加数据时,使用
setLimit分批从数据库读取数据,然后分批添加到索引,避免内存溢出。 - 优化服务器配置:确保服务器有足够的内存和磁盘空间给 Xunsearch。
- 调整
ini配置:可以调整general段落的memory_limit等参数。
Q: 搜索结果不准确怎么办?
A:
- 调整字段权重:提高重要字段的
weight值。 - 使用自定义词典:添加行业术语或专有名词,确保分词正确。
- 使用停用词词典:过滤掉干扰词。
- 调整搜索算法:尝试使用
fuzzy模糊搜索或pinyin拼音搜索。
Q: 如何在项目中集成?
A:
- 封装成服务类:创建一个
XunsearchService类,对外提供add,update,del,search等方法,内部封装XS的操作。 - 结合 MVC 框架:在 Laravel, ThinkPHP 等框架中,可以创建一个 Service Provider 或 Facade,方便在控制器中调用。
- 使用队列:对于数据的更新,可以将任务推送到队列(如 Redis Queue, RabbitMQ),由后台消费者进程来执行索引的添加和刷新,避免阻塞 Web 请求。
总结与资源
Xunsearch 是一个值得学习的工具,它为 PHP 应用提供了企业级的全文检索能力,通过本教程,你应该已经掌握了从安装配置到基本搜索,再到进阶优化的全过程。
官方资源
- Xunsearch 官网: 最权威的文档和下载地址。
- 官方文档: API 手册和配置详解,必看。
- 官方社区: 遇到问题时,可以在这里提问。
学习建议
- 动手实践:跟着教程敲一遍代码,然后尝试修改
ini文件,添加新字段,观察搜索行为的变化。 - 阅读官方文档:官方文档是最好的老师,特别是配置选项部分。
- 从简单到复杂:先实现一个基础的站内搜索,再逐步加入排序、高亮、拼音等高级功能。
希望这份教程对你有帮助!祝你在使用 Xunsearch 的过程中一切顺利!


