MySQL Cluster 教程:从零开始构建高可用、高可扩展数据库
目录
- 第一部分:MySQL Cluster 核心概念
- 1. 什么是 MySQL Cluster?
- 2. 与传统主从复制的区别
- 3. NDB 存储引擎:内存中的奇迹
- 4. MySQL Cluster 的核心架构
- 第二部分:动手实践:搭建一个最小可用集群
- 1. 环境规划
- 2. 系统环境准备
- 3. 安装 MySQL Cluster 软件
- 4. 配置管理节点 (
config.ini) - 5. 启动集群
- 6. 配置 SQL 节点并连接测试
- 第三部分:深入理解与进阶
- 1. 集群管理 (
ndb_mgm) - 2. 数据分区与数据节点
- 3. 备份与恢复
- 4. 监控与故障排查
- 1. 集群管理 (
- 第四部分:最佳实践与注意事项
- 1. 硬件建议
- 2. 网络要求
- 3. 何时选择 MySQL Cluster?
- 第五部分:总结与资源
第一部分:MySQL Cluster 核心概念
1. 什么是 MySQL Cluster?
MySQL Cluster 是 MySQL 官方提供的一个高性能、高可用、高可扩展的共享-nothing(无共享)集群数据库解决方案,它的核心目标是实现内存级数据处理和999% 的高可用性。
它不是一个简单的“主从复制”方案,而是一个将数据完全内存化、并在多台物理服务器上分布式存储的数据库集群。
2. 与传统主从复制的区别
| 特性 | MySQL Cluster (NDB) | 传统主从复制 |
|---|---|---|
| 数据一致性 | 强一致性 (Synchronous) | 最终一致性 (Asynchronous) |
| 复制方式 | 基于行的、同步的、多主复制 | 基于二进制日志的、异步的、单主复制 |
| 数据存储 | 内存为主,磁盘为持久化备份 | 磁盘为主,I/O 是瓶颈 |
| 架构 | 共享-nothing,无单点故障 | 主库是单点故障,从库只读 |
| 扩展性 | 水平扩展(增加数据节点) | 主要是读扩展(增加从库),写扩展困难 |
| 延迟 | 极低,微秒级 | 取决于网络和负载,可能较高 |
| 应用场景 | 金融、电信、在线游戏等对性能和可用性要求极高的场景 | Web 应用、报表系统、读写分离场景 |
- 主从复制:像一个大老板(主库)把工作指令(写操作)记在日记本(Binlog)上,然后让小弟们(从库)去执行,小弟们执行有快有慢,日记本丢了就全完了。
- MySQL Cluster:像一个议会(数据节点),每个议员都有一份完整的会议记录(数据),每次决策(写操作)都必须所有议员一致同意才能通过,一个议员病倒了(节点故障),会议照常进行,因为其他议员都有记录。
3. NDB 存储引擎:内存中的奇迹
MySQL Cluster 的核心是 NDB (Network Database) 存储引擎,它的数据主要存储在内存中,这使得读写速度极快,远超传统的磁盘数据库。
- 内存表:所有表默认都使用 NDB 存储引擎,数据驻留在内存。
- 磁盘数据:为了防止断电数据丢失,NDB 会将数据以检查点的形式异步写入磁盘,还支持将非索引列和大型文本/二进制对象(BLOB/TEXT)直接存储在磁盘上,以平衡内存使用和性能。
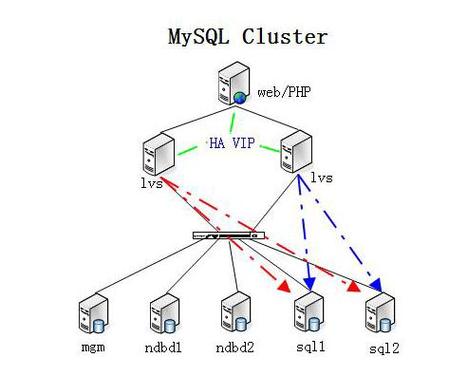
4. MySQL Cluster 的核心架构
一个典型的 MySQL Cluster 至少包含三种类型的节点:
-
管理节点
- 作用:集群的大脑,负责启动、停止、配置和监控所有其他节点。
- 软件:
ndb_mgmd。 - 数据:存储集群的配置文件 (
config.ini)。
-
数据节点
- 作用:集群的核心,负责存储数据和处理数据请求,数据在数据节点之间进行分区和复制。
- 软件:
ndbd。 - 数据:实际的数据和索引存储在节点的内存中。
-
SQL 节点
- 作用:对外提供标准的 MySQL 服务,应用程序通过它来连接数据库,执行 SQL 语句,它本身不存储数据,而是将请求转发给合适的数据节点。
- 软件:标准的 MySQL Server (
mysqld),并配置使用 NDB 存储引擎。 - 数据:无,仅处理查询和请求。
数据分区与复制机制:
- 分区:一张大表会被水平切分成多个 分区,每个分区存储在不同的数据节点上,这实现了 I/O 和查询的并行处理,极大地提升了性能和扩展性。
- 复制:为了高可用,每个分区都会有至少一个副本,存储在不同的数据节点上,当某个数据节点宕机时,它的副本会立即接管服务,实现自动故障转移。
第二部分:动手实践:搭建一个最小可用集群
我们将搭建一个包含 1个管理节点、2个数据节点、2个SQL节点 的最小高可用集群,这种架构可以容忍任何一个数据节点的故障。
1. 环境规划
| 节点类型 | 主机名 | IP 地址 | 操作系统 | 软件 |
|---|---|---|---|---|
| 管理节点 | mgmd-01 |
168.1.10 |
Ubuntu 20.04 LTS | ndb_mgmd, mysql-cluster |
| 数据节点 1 | ndbd-01 |
168.1.20 |
Ubuntu 20.04 LTS | ndbd, mysql-cluster |
| 数据节点 2 | ndbd-02 |
168.1.21 |
Ubuntu 20.04 LTS | ndbd, mysql-cluster |
| SQL 节点 1 | sql-01 |
168.1.30 |
Ubuntu 20.04 LTS | mysqld (with NDB) |
| SQL 节点 2 | sql-02 |
168.1.31 |
Ubuntu 20.04 LTS | mysqld (with NDB) |
2. 系统环境准备
在所有节点上执行以下操作:
-
设置主机名
# 在 mgmd-01 上 sudo hostnamectl set-hostname mgmd-01 # 在 ndbd-01 上 sudo hostnamectl set-hostname ndbd-01 # ...以此类推
-
配置
/etc/hosts文件 在所有节点的/etc/hosts文件中添加以下内容,以便通过主机名互相通信:168.1.10 mgmd-01 192.168.1.20 ndbd-01 192.168.1.21 ndbd-02 192.168.1.30 sql-01 192.168.1.31 sql-02 -
创建 MySQL 用户和目录
sudo useradd -r -s /bin/false mysql sudo mkdir -p /var/lib/mysql-cluster sudo chown -R mysql:mysql /var/lib/mysql-cluster
-
配置防火墙 (ufw) 在所有节点上开放必要端口:
# 管理节点 (默认端口 1186) sudo ufw allow 1186/tcp # 数据节点之间通信 (默认端口 2202, 2201, 1102, 1101, 1028) sudo ufw allow 2202/tcp sudo ufw allow 2201/tcp sudo ufw allow 1102/tcp sudo ufw allow 1101/tcp # SQL 节点连接数据节点 (默认端口 3306, 3307, 3308...) sudo ufw allow 3306/tcp # 启用防火墙 sudo ufw enable
3. 安装 MySQL Cluster 软件
在所有节点上添加 MySQL APT 仓库并安装。
-
下载并添加 APT 仓库
# 下载 MySQL APT 仓库配置包 wget https://dev.mysql.com/get/mysql-apt-config_0.8.22-1_all.deb # 安装配置包 (会弹出界面,选择 "Ok",然后选择 "mysql-cluster-8.0" 版本) sudo dpkg -i mysql-apt-config_* # 更新软件包列表 sudo apt update
-
安装 MySQL Cluster
# 安装管理节点和数据节点软件 sudo apt install mysql-cluster-community-data-node mysql-cluster-management-client # 安装 SQL 节点软件 sudo apt install mysql-cluster-community-server
4. 配置管理节点 (config.ini)
这是集群配置的核心,在管理节点 (mgmd-01)上操作。
-
创建配置文件
sudo nano /var/lib/mysql-cluster/config.ini
-
粘贴以下配置
[ndbd default] # 数据节点之间的数据复制数,2表示每个数据分区有一个副本 NoOfReplicas=2 # 数据节点数据目录 DataMemory=512M # 索引内存大小 IndexMemory=128M # TCP/IP 缓冲区大小 SocketBuffer=1G # 节点故障后,重启超时时间 StartFatalErrorTimeout=10 [ndb_mgmd] # 管理节点主机名和端口 hostname=mgmd-01 datadir=/var/lib/mysql-cluster [ndbd] # 数据节点1 hostname=ndbd-01 datadir=/usr/local/mysql/data NodeId=1 [ndbd] # 数据节点2 hostname=ndbd-02 datadir=/usr/local/mysql/data NodeId=2 [mysqld] # SQL节点1 hostname=sql-01 NodeId=10 [mysqld] # SQL节点2 hostname=sql-02 NodeId=11
说明:
NoOfReplicas=2是高可用的关键,意味着每个数据分区至少有一份副本。- 每个节点都需要唯一的
NodeId。 datadir指定了每个节点的数据存储路径。
5. 启动集群
-
启动管理节点 在
mgmd-01上执行:sudo ndb_mgmd -f /var/lib/mysql-cluster/config.ini --initial
-f指定配置文件。--initial非常重要!第一次启动或配置文件发生重大变更时使用,它会清空所有节点的旧数据,后续重启请不要使用此参数。
-
启动数据节点 在
ndbd-01和ndbd-02上分别执行:sudo systemctl start ndbd # 检查状态 sudo systemctl status ndbd
-
启动 SQL 节点 在
sql-01和sql-02上分别执行:sudo systemctl start mysql # 检查状态 sudo systemctl status mysql
-
检查集群状态 在
mgmd-01上连接管理客户端:ndb_mgm
在
ndb_mgm>提示符下输入SHOW命令,你应该能看到所有节点都已连接并处于Started状态。-- NDB Cluster -- Management Client -- ndb_mgm> SHOW Connected to Management at: 192.168.1.10:1186 Cluster Configuration --------------------- [ndbd(NDB)] 2 node(s) id=1 @192.168.1.20 (mysql-5.7.34 ndb-8.0.25, Nodegroup: 0, Master) id=2 @192.168.1.21 (mysql-5.7.34 ndb-8.0.25, Nodegroup: 0) [ndb_mgmd(MGM)] 1 node(s) id=10 @192.168.1.10 (Version: 8.0.25) [mysqld(API)] 2 node(s) id=11 @192.168.1.30 (Version: 8.0.25) id=12 @192.168.1.31 (Version: 8.0.25) ndb_mgm>输入
EXIT退出。
6. 配置 SQL 节点并连接测试
-
获取 SQL 节点 root 密码 在
sql-01和sql-02上执行:sudo cat /etc/mysql/debian.cnf
用这里的用户名和密码登录 MySQL。
-
创建测试用户和数据库
-- 登录到任何一个 SQL 节点,sql-01 mysql -u debian-sys-maint -p -- 创建一个测试用户 CREATE USER 'cluster_user'@'%' IDENTIFIED BY 'your_password'; -- 创建一个测试数据库 CREATE DATABASE my_cluster_db; -- 授权 GRANT ALL PRIVILEGES ON my_cluster_db.* TO 'cluster_user'@'%'; FLUSH PRIVILEGES;
-
创建 NDB 表并测试
USE my_cluster_db; -- 必须显式使用 NDB 存储引擎 CREATE TABLE users ( id INT UNSIGNED NOT NULL AUTO_INCREMENT, name VARCHAR(50) NOT NULL, email VARCHAR(100), PRIMARY KEY (id) USING HASH, INDEX (name) USING HASH ) ENGINE=NDB; -- 插入数据 INSERT INTO users (name, email) VALUES ('Alice', 'alice@example.com'); INSERT INTO users (name, email) VALUES ('Bob', 'bob@example.com'); -- 查询数据 SELECT * FROM users; -
高可用测试
- 在
sql-01上查询数据。 - 停止
ndbd-01数据节点:在mgmd-01上执行ndb_mgm,然后输入RESTART 1或直接在ndbd-01上sudo systemctl stop ndbd。 - 再次在
sql-01上执行SELECT * FROM users;,你会发现查询依然成功,数据没有丢失,服务未中断,这证明了集群的高可用性。
- 在
第三部分:深入理解与进阶
1. 集群管理 (ndb_mgm)
ndb_mgm 是管理集群的命令行工具。
SHOW: 显示集群状态。START <node_id>: 启动指定节点。STOP <node_id>: 停止指定节点(安全停止,数据会同步)。RESTART <node_id>: 重启指定节点(不安全,可能导致数据不一致,除非配置了Arbitration)。ENTER SINGLE USER MODE: 进入单用户模式,用于维护。EXIT: 退出客户端。
2. 数据分区与数据节点
- 分区:数据根据主键的哈希值被分配到不同的分区,分区数由
DataMemory和FragmentLogPartSize等参数决定。 - 节点组:每个分区及其副本组成一个节点组。
NoOfReplicas=2时,一个节点组包含 2 个数据节点,节点组分布在不同的物理机器上,以实现容错。
3. 备份与恢复
-
创建备份 在
ndb_mgm中执行:ndb_mgm> START BACKUP备份文件会保存在所有数据节点的
DataDir目录下,你需要从其中一个节点收集这些文件。BACKUP-backup_id-0.ndb: 数据文件。BACKUP-backup_id-1.ndb: 元数据文件。BACKUP-backup_id-2.ndb: 日志文件。BACKUP-backup_id-3.cpbackup: 备份元数据。
-
恢复备份 这是一个复杂的过程,通常需要停止所有 SQL 节点,然后使用
ndb_restore工具在数据节点上执行恢复命令。
4. 监控与故障排查
-
SHOW命令:最直接的状态检查。 -
information_schema:查询ndb_*相关的表,如ndb_transid_mysql_connection_pool、ndb_status等,获取详细运行时信息。 -
ndbinfo数据库:提供了更丰富的性能和状态信息,是监控的首选。-- 查看集群状态 SELECT * FROM ndbinfo.cluster_status; -- 查看各节点状态 SELECT * FROM ndbinfo.nodes;
-
日志文件:
- 管理节点日志:
/var/lib/mysql-cluster/cluster.log - 数据节点日志:通常在
/var/log/mysql/或/usr/local/mysql/data/下。
- 管理节点日志:
第四部分:最佳实践与注意事项
1. 硬件建议
- 内存:足够大,确保
DataMemory+IndexMemory+ 操作系统所需,建议使用 ECC 内存。 - CPU:核心数越多越好,用于并行处理。
- 网络:至关重要!必须使用低延迟、高带宽的专用网络(最好是 10GbE 或更高),避免使用公共网络或与业务流量混合。
- 磁盘:对于数据节点,使用高性能的本地 SSD 或 NVMe,用于存储检查点和日志,对于 SQL 节点,磁盘性能也很重要。
2. 网络要求
- 交换机:支持组播或多播,如果网络环境不支持,需要配置
TCP传输,但这会影响性能。 - 隔离:管理节点、数据节点、SQL 节点的流量最好在独立的 VLAN 或子网中。
3. 何时选择 MySQL Cluster?
选择 MySQL Cluster:
- 需要999% 及以上的可用性,且不能接受数据丢失。
- 对写入延迟要求极其苛刻,必须是毫秒甚至微秒级。
- 数据量巨大,需要线性水平扩展能力。
- 应用本身就是分布式的,需要数据库本身支持分布式事务。
不选择 MySQL Cluster:
- 大多数 Web 应用场景,传统的主从复制 + MHA/Orchestrator + ProxySQL 方案已经足够成熟且成本更低。
- 读多写少的场景,MySQL Cluster 的写入开销比普通 MySQL 大。
- 预算有限,无法满足其严格的硬件和网络要求。
- 数据库以事务性为主,但不需要跨多个分区的分布式事务(此时考虑 InnoDB Cluster/Galera Cluster)。
第五部分:总结与资源
MySQL Cluster 是一个功能强大但部署和维护复杂的系统,它通过将数据完全内存化和分布式存储,实现了无与伦比的高性能和高可用性。
关键要点回顾:
- 架构清晰:理解 MGM、NDB、SQL 三种节点的角色。
- 强一致性:同步复制是其核心优势,区别于异步的主从复制。
- 内存为王:NDB 引擎的性能源于内存,但也要关注磁盘持久化。
- 网络是生命线:糟糕的网络会毁掉整个集群。
- 配置是关键:
config.ini文件是集群的灵魂,务必仔细配置。
官方资源:
- MySQL Cluster 官方文档: https://dev.mysql.com/doc/cluster-8.0/en/ (这是最权威的资料)
- MySQL 官方下载: https://www.mysql.com/downloads/cluster/
这份教程为你提供了一个坚实的基础,要真正掌握 MySQL Cluster,还需要在实践中不断探索、测试和优化,祝你成功!


