Pyppeteer 教程:从入门到精通
Pyppeteer 是一个 Python 库,它是对 Google 开源的无头浏览器 Chromium 的封装,你可以用 Python 代码来控制一个真实的浏览器(Chrome)进行各种自动化操作,比如点击、输入、滚动、截图、生成 PDF 等,它非常适合用于 Web 自动化测试、网络爬虫(特别是处理 JavaScript 渲染的页面)、性能监控等场景。

目录
- 为什么选择 Pyppeteer?
- 环境准备与安装
- 第一个 Pyppeteer 程序:Hello World
- 核心概念详解
Browser(浏览器实例)Page(页面/标签页)Target和BrowserContext(上下文)ElementHandle和JSHandle(元素句柄)
- 常用 API 实战
- 打开网页
- 获取页面信息
- 元素选择与交互
- 处理弹窗
- 页面操作
- 等待机制
- 截图与生成 PDF
- 执行 JavaScript
- 实战案例:爬取知乎热榜
- 高级技巧与最佳实践
- 使用选择器
- 处理 iframe
- 拦截网络请求
- 设置代理
- 无头模式与可视化模式
- 异常处理
- 总结与资源
为什么选择 Pyppeteer?
- 强大的 JavaScript 渲染能力:可以完美抓取由 JavaScript 动态生成内容的网页,这是传统
requests+BeautifulSoup无法做到的。 - 接近真人浏览:模拟真实用户行为,如点击、移动鼠标、填写表单等,能有效反爬。
- 功能全面:除了爬取,还能进行网页截图、生成 PDF、执行性能分析、自动化测试等。
- 跨平台:基于 Chromium,可在 Windows, macOS, Linux 等系统上运行。
环境准备与安装
安装 Pyppeteer
Pyppeteer 通过 pip 安装非常简单:
pip install pyppeteer
下载 Chromium (重要!)
Pyppeteer 在安装时不会自动下载 Chromium 浏览器,当你第一次运行 Pyppeteer 代码时,它会自动从官方源下载一个与你的系统匹配的 Chromium 版本,这个过程只需要进行一次。
注意:由于网络原因,下载可能会很慢或失败,你可以手动下载并指定路径,但这通常不是必需的。
环境变量(可选)
你可以通过设置环境变量 PYPPETEER_HOME 来指定 Chromium 的下载和存放路径。
# Linux / macOS export PYPPETEER_HOME=/path/to/my/chromium # Windows (Command Prompt) set PYPPETEER_HOME=C:\path\to\my\chromium
第一个 Pyppeteer 程序:Hello World
让我们从一个最简单的例子开始:打开一个网页,然后截图。
import asyncio
from pyppeteer import launch
async def main():
# 1. 启动浏览器
# headless=False 表示有界面模式,方便调试
browser = await launch(headless=False)
# 2. 创建一个新的页面
page = await browser.newPage()
# 3. 设置视口大小,某些网站需要
await page.setViewport({'width': 1280, 'height': 800})
# 4. 访问目标网页
await page.goto('https://www.example.com')
# 5. 截图并保存
await page.screenshot({'path': 'example.png'})
# 6. 获取页面标题= await page.title()
print(f"Page Title: {title}")
# 7. 关闭浏览器
await browser.close()
# 运行主函数
asyncio.get_event_loop().run_until_complete(main())
代码解释:
import asyncio:Pyppeteer 是一个异步库,必须使用asyncio来运行。from pyppeteer import launch:从库中导入launch函数,用于启动浏览器。await launch(...):launch是一个异步函数,返回一个Browser对象。headless=False会让浏览器以有界面形式打开,方便你观察操作过程,在生产环境中,通常设置为True。await browser.newPage():在浏览器中创建一个新的标签页,返回一个Page对象,后续所有页面操作都基于这个对象。await page.goto(url):导航到指定的 URL。await page.screenshot(...):对当前页面进行截图并保存到指定路径。await page.title():获取页面的<title>标签内容。await browser.close():关闭浏览器,释放资源。
运行此代码后,你会看到一个 Chrome 浏览器窗口闪现,访问 example.com,然后关闭,你的项目目录下会生成一张 example.png 截图。
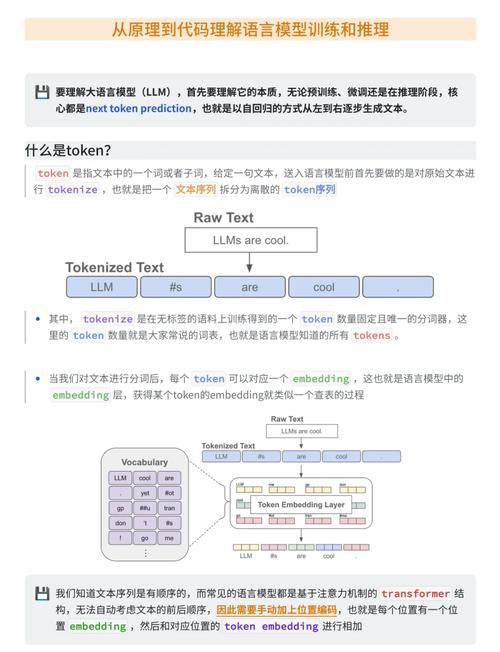
核心概念详解
Browser (浏览器实例)
这是通过 launch() 函数创建的对象,代表整个浏览器进程,你可以用它来创建新页面、管理浏览器设置、关闭浏览器等。
Page (页面/标签页)
这是 Browser.newPage() 创建的对象,代表浏览器中的一个标签页,绝大多数与用户交互相关的 API 都在 Page 对象上,如 goto, click, type, waitForSelector 等。
Target 和 BrowserContext (上下文)
BrowserContext:可以理解为浏览器的一个“用户配置文件”或“会话”,它隔离了缓存、Cookie 和 localStorage,你可以创建多个BrowserContext来模拟不同的登录用户,它们之间互不干扰。Target:代表一个可以导航的目标,通常是Page(标签页)或Background Page(后台页)。
# 创建一个新的上下文 context = await browser.createIncognitoBrowserContext() # 无痕模式 page = await context.newPage() # ... 在这个 page 上操作 ... await context.close() # 关闭上下文,会自动关闭其所有页面
ElementHandle 和 JSHandle (元素句柄)
当你通过 page.querySelector() 等方法获取页面上的一个元素或一个 JavaScript 对象时,你得到的是一个句柄,而不是直接的元素数据,句柄是一个指向浏览器中真实对象的引用。
ElementHandle:指向一个 DOM 元素(如<div>,<a>)的句柄,你可以用它来对这个元素进行点击、输入等操作。JSHandle:指向一个 JavaScript 对象(可以是 DOM 元素,也可以是数字、字符串、数组等)的句柄。
# 获取一个元素的句柄
element_handle = await page.querySelector('h1')
# 获取元素的文本内容
# 方法1: 使用 evaluateHandle 执行 JS 并获取 JSHandle
js_handle = await page.evaluateHandle('element => element.textContent', element_handle)
text = await js_handle.jsonValue() # 将 JSHandle 转换为 Python 对象
# 方法2: 更简洁的方式 (推荐)
text = await page.evaluate('element => element.textContent', element_handle)
常用 API 实战
打开网页
await page.goto('https://www.google.com', {'waitUntil': 'networkidle0'})
waitUntil:等待条件,'networkidle0'是一个很好的选择,它会等待页面没有超过 0 个的网络连接(即所有请求都完成)后再继续执行。
获取页面信息
url = page.url # 当前页面 URL
content = await page.content() # 页面的完整 HTML 内容元素选择与交互
这是爬虫中最核心的部分。
选择器:
page.querySelector(selector):返回第一个匹配元素的ElementHandle。page.querySelectorAll(selector):返回所有匹配元素的ElementHandle列表。page.xpath(xpath_expression):使用 XPath 选择器。
交互:
await page.click(selector):点击元素。await page.type(selector, 'text', {'delay': 100}):在输入框中输入文本,delay可以模拟打字速度。await page.focus(selector):聚焦到元素。await page.select(selector, 'option1', 'option2'):选择下拉框的选项。
示例:模拟在百度搜索
import asyncio
from pyppeteer import launch
async def main():
browser = await launch(headless=False)
page = await browser.newPage()
await page.goto('https://www.baidu.com')
# 找到搜索框并输入 "Pyppeteer"
await page.type('#kw', 'Pyppeteer')
# 找到“百度一下”按钮并点击
await page.click('#su')
# 等待搜索结果加载
await page.waitForSelector('div#content_left') # 等待一个元素出现
# 获取搜索结果的标题s = await page.querySelectorAll('div#content_left h3')
for title in titles:
text = await page.evaluate('(element) => element.innerText', title)
print(text)
await browser.close()
asyncio.get_event_loop().run_until_complete(main())
处理弹窗
page.on('dialog', lambda dialog: dialog.accept()):监听并自动接受所有对话框(alert,confirm)。dialog.dismiss():拒绝对话框。
async def handle_dialog(dialog):
print(f"Dialog message: {dialog.message}")
await dialog.accept() # 或者 await dialog.dismiss()
page.on('dialog', handle_dialog)
页面操作
await page.goBack():后退await page.goForward():前进await page.reload():刷新await page.waitForNavigation():等待页面跳转完成,通常与点击链接等操作一起使用。
# 点击一个链接,并等待新页面加载
await Promise.all([
page.waitForNavigation(), # 等待导航完成
page.click('a.some-link') # 触发导航
])
等待机制
这是 Pyppeteer 自动化中最关键也最容易出错的部分,直接 click() 可能会因为元素未加载而失败。
- 隐式等待:
page.setDefaultNavigationTimeout(timeout)设置全局超时时间。 - 智能等待 (推荐):
page.waitForSelector(selector):等待一个元素出现在 DOM 中。page.waitForFunction(js_function):等待一个 JavaScript 函数返回true。page.waitForTimeout(milliseconds):等待指定毫秒(不推荐,除非必要)。page.waitForResponse(url_or_predicate):等待特定的网络响应。
截图与生成 PDF
# 截图
await page.screenshot({'path': 'fullpage.png', 'fullPage': True}) # 整页截图
# 生成 PDF
await page.pdf({'path': 'page.pdf', 'format': 'A4', 'printBackground': True})
执行 JavaScript
page.evaluate() 是一个非常强大的函数,它允许你在当前页面的上下文中执行 JavaScript 代码,并返回结果。
# 获取页面的所有链接
links = await page.evaluate('''
() => {
const anchors = document.querySelectorAll('a');
return Array.from(anchors).map(a => a.href);
}
''')
print(links)
# 修改页面样式
await page.evaluate('() => document.body.style.backgroundColor = "red"')
实战案例:爬取知乎热榜
这个案例将综合运用所学知识,爬取知乎热榜的标题、链接和热度。
目标:https://www.zhihu.com/hot
import asyncio
import json
from pyppeteer import launch
async def main():
browser = await launch(headless=True) # 使用无头模式
page = await browser.newPage()
await page.setViewport({'width': 1366, 'height': 768})
# 访问知乎热榜
await page.goto('https://www.zhihu.com/hot', {'waitUntil': 'networkidle0'})
# 等待榜单加载
await page.waitForSelector('HotItem')
# 使用 XPath 获取所有热榜条目
# 知乎的 HotItem 组件的 XPath 是 //*/div[@class="HotItem"]
items = await page.xpath('//*[@class="HotItem"]')
hot_list = []
for item in items:
# 提取标题
title_element = await item.querySelector('a')
title = await page.evaluate('(element) => element.innerText', title_element) if title_element else 'N/A'
# 提取链接
link = await page.evaluate('(element) => element.href', title_element) if title_element else 'N/A'
# 提取热度
heat_element = await item.querySelector('span')
heat = await page.evaluate('(element) => element.innerText', heat_element) if heat_element else 'N/A'
hot_list.append({
'title': title,
'link': link,
'heat': heat
})
# 将结果格式化输出
print(json.dumps(hot_list, ensure_ascii=False, indent=2))
await browser.close()
asyncio.get_event_loop().run_until_complete(main())
高级技巧与最佳实践
使用选择器
始终优先使用 id、class、data-testid 等稳定的选择器,避免使用易变的 CSS 选择器(如 nth-child(n))。
处理 iframe
如果目标元素在 <iframe> 内,你需要先切换到 iframe 的上下文。
# 获取 iframe 的句柄
iframe_handle = await page.querySelector('iframe#my-iframe')
# 切换到 iframe
await page.frame('my-iframe') # 通过 name 或 id
# 或者
await page.frame(iframe_handle) # 通过句柄
# 现在所有 page 操作都将在 iframe 内部生效
# 操作完后,如果想切回主页面
# await page.goto('about:blank') # 一种简单粗暴的方法
# 或者使用 page.frames() 获取所有 frame 对象,再切换回来
拦截网络请求
你可以拦截特定类型的请求(如图片、广告脚本),以提高加载速度。
async def intercept_request(request):
if request.resourceType == 'image':
await request.abort() # 中止请求
else:
await request.continue_() # 继续请求
page.on('request', intercept_request)
设置代理
browser = await launch({
'args': [
'--proxy-server=http://your-proxy-address:port'
]
})
无头模式与可视化模式
headless=True:无头模式,后台运行,不显示浏览器界面。生产环境推荐。headless=False:有头模式,显示浏览器界面。调试时推荐。
异常处理
网络请求和页面操作都可能失败,务必使用 try...except 进行包裹。
try:
await page.goto('https://some-slow-site.com', {'timeout': 5000}) # 设置超时
await page.waitForSelector('.some-element', {'timeout': 3000})
except Exception as e:
print(f"An error occurred: {e}")
# 执行错误处理逻辑,如截图记录错误现场
await page.screenshot({'path': 'error.png'})
总结与资源
Pyppeteer 是一个功能极其强大的工具,它让 Python 控制浏览器变得轻而易举,通过本教程,你应该已经掌握了它的基本用法和核心技巧。
官方资源:
- Pyppeteer GitHub 仓库 (文档和 Issue)
- Chromium DevTools Protocol (Pyppeteer 的底层 API 参考)
学习建议:
- 多动手实践:跟着教程敲代码,并尝试修改、扩展。
- 善用浏览器开发者工具:在
headless=False模式下,打开浏览器的开发者工具(F12),观察网络请求、元素结构,这能帮助你更好地定位元素和理解页面加载过程。 - 阅读官方文档:API 更新很快,遇到问题时,第一手资料永远是官方文档。
希望这份教程对你有帮助!祝你使用 Pyppeteer 顺利!


