- 准备工作:确保你已安装好必要软件。
- 分析目标网站:了解站壳网的文章结构,这是最关键的一步。
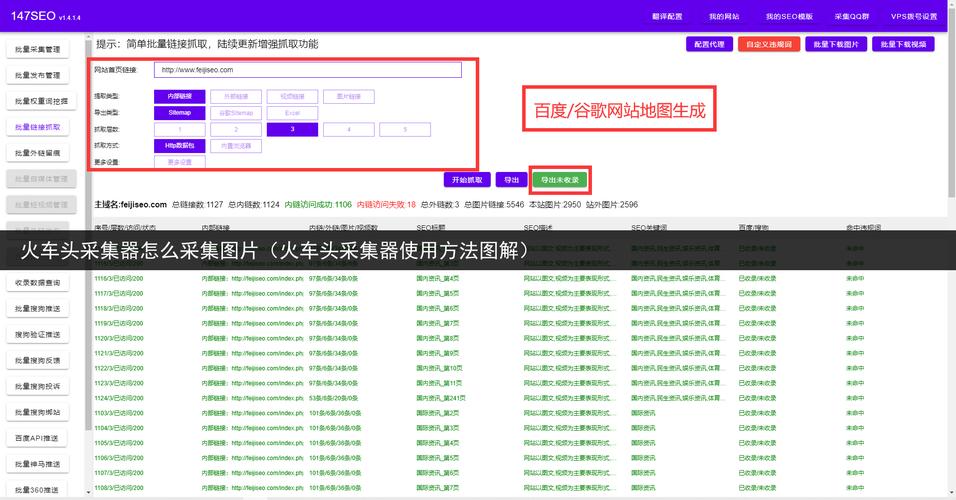
- 创建和配置采集任务:在火车头中进行详细设置。
- 设置发布规则:将采集到的内容发布到你的WordPress网站。
- 测试与优化:如何验证采集效果并处理常见问题。
第一部分:准备工作
在开始之前,请确保你已经准备好以下工具:
(图片来源网络,侵删)
- 火车头采集器 (Train Head):在你的电脑上安装并运行火车头客户端,你可以从火车头官网下载。
- 火车头发布模块 (Train Post):这个模块负责将采集到的内容发布到你的网站,它通常是一个独立的插件,需要安装在你的WordPress网站上。
- 下载:从火车头官网下载
Train Post插件。 - 安装:登录你的WordPress后台,进入
插件->上传插件,选择下载的Train Post.zip文件进行安装并激活。
- 下载:从火车头官网下载
- 目标网站:一个可以用来测试的WordPress网站,以及站壳网的访问权限。
- 浏览器:推荐使用 Chrome 或 Firefox,并安装 “查看网页源代码” 或类似的插件,方便分析网页结构。
第二部分:分析目标网站(站壳网)
这是整个采集过程的核心,我们需要找出文章列表页、文章详情页以及标题、内容、图片等元素的“地址”。
-
找到列表页 URL
- 打开站壳网,主题”分类页面:
https://www.zhancoo.com/theme - 这个页面的 URL 就是我们采集任务的“起始网址”,火车头会抓取这个页面,从中提取所有文章的详情页链接。
- 打开站壳网,主题”分类页面:
-
分析文章详情页结构
-
随便打开一篇站壳网的文章,
https://www.zhancoo.com/wordpress-theme/flash.html (图片来源网络,侵删)
(图片来源网络,侵删) -
按
F12打开开发者工具,或者使用“查看网页源代码”插件,我们来定位关键元素。 -
- 在浏览器中,右键点击文章标题,选择“检查”。
- 你会发现标题被包含在一个
<h1 class="article-title">标签里。 - 采集规则:
h1.article-title(使用 CSS 选择器)
-
发布日期:
- 右键点击发布日期,选择“检查”。
- 它通常在一个
<span class="article-time">标签里。 - 采集规则:
span.article-time(CSS 选择器)
-
:
- 右键点击文章正文内容,选择“检查”。
- 你会发现正文内容主要在一个
<div class="article-content">标签里。注意:这个div里可能包含<p>、<img>、<h2>等各种标签,我们希望保留它们。 - 采集规则:
div.article-content(CSS 选择器)
-
文章缩略图:
 (图片来源网络,侵删)
(图片来源网络,侵删)- 右键点击文章顶部的封面图,选择“检查”。
- 它的
src属性(图片地址)通常在一个<img>标签里,并且这个img标签在一个<div class="article-thumb">里。 - 采集规则:
div.article-thumb img(CSS 选择器)
-
下载链接:
- 站壳网的下载链接通常是一个按钮,百度网盘下载”。
- 右键点击这个按钮,选择“检查”。
- 它的
href属性(链接地址)通常在一个<a>标签里,并且这个a标签有一个特定的 class,btn btn-primary。 - 采集规则:
a.btn.btn-primary(CSS 选择器)
-
总结一下分析结果:
| 字段 | 采集规则 (CSS 选择器) | 说明 |
| :--- | :--- | :--- || h1.article-title | 文章主标题 |
| 发布日期 | span.article-time | 发布时间 || div.article-content | 包含所有段落、图片、格式的内容 |
| 缩略图 | div.article-thumb img | 文章封面图 |
| 下载链接 | a.btn.btn-primary | 主题/插件下载链接 |
第三部分:创建和配置采集任务
我们打开火车头采集器,开始创建任务。
-
新建任务
- 点击
文件->新建任务,给任务起个名字,采集站壳网主题”。
- 点击
-
设置基本参数
- 起始网址:填入我们找到的列表页 URL,
https://www.zhancoo.com/theme。 - 编码:选择
UTF-8(站壳网使用UTF-8编码)。 - 采集网址:选择
列表,因为我们是从一个列表页开始,然后抓取里面的所有文章链接。
- 起始网址:填入我们找到的列表页 URL,
-
设置采集字段
- 在“采集字段”区域,点击 号,添加我们分析出的所有字段:、
发布日期、、缩略图、下载链接。
- 在“采集字段”区域,点击 号,添加我们分析出的所有字段:、
-
配置字段规则
-
列表页循环规则:
- 点击
列表页标签页。 - 在
列表循环输入框中,我们需要找到包裹每篇文章链接的父级元素,观察站壳网列表页,每篇文章的链接都在一个<div class="excerpt">里。 - 列表循环规则:
div.excerpt
- 点击
-
文章链接规则:
- 在
文章链接输入框中,找到上面循环元素里的具体链接标签,它是一个<a>- 文章链接规则:
a(它会自动提取href属性) - 文章链接规则:
- 在
-
详情页字段规则:
- 点击
详情页标签页。 - ”字段的“规则”一栏,输入我们分析出的 CSS 选择器:
h1.article-title。 - 发布日期:规则输入
span.article-time。 - 规则输入
div.article-content。 - 缩略图:规则输入
div.article-thumb img。 - 下载链接:规则输入
a.btn.btn-primary。
- 点击
-
-
设置分页
- 站壳网有“下一页”按钮,点击
分页标签页。 - 分页循环:找到包含“下一页”按钮的父元素,通常是
<div class="pagination">。 - 分页循环规则:
div.pagination - 下一页链接:找到“下一页”按钮的
<a>- 下一页链接规则:
a.next - 下一页链接规则:
- 站壳网有“下一页”按钮,点击
-
保存任务
- 点击
文件->保存任务,任务配置到这里就完成了。
- 点击
第四部分:设置发布规则
这一步是将火车头采集到的内容,通过 Train Post 插件发送到你的WordPress网站。
-
获取发布接口地址
- 登录你的WordPress网站后台。
- 找到
Train Post插件的设置页面(通常在设置->Train Post)。 - 你会看到一个 “发布接口地址”,它看起来像
https://你的网站域名/index.php?module=trainpost。 - 复制这个地址,稍后要用。
-
在火车头中配置发布
- 回到火车头采集器,在任务窗口底部找到
发布设置标签页并点击。 - 发布接口地址:将刚才复制的WordPress接口地址粘贴到这里。
- 发布方式:选择
Post(发布文章)。 - 发布字段映射:这是最关键的一步,它决定了火车头采集到的数据对应到WordPress的哪个字段。
- ->
post_title - ->
post_content - 发布日期 ->
post_date - 缩略图 ->
post_thumbnail(你需要勾选“下载图片并设置为特色图”) - 下载链接 -> 这是一个自定义字段,你可以创建一个新的字段,
meta_down_link,然后在这里选择它。
- ->
- 回到火车头采集器,在任务窗口底部找到
-
设置文章分类
- 在
发布设置中,找到分类选项。 - 你可以指定文章发布到哪个分类ID,你创建了一个名为“WordPress主题”的分类,ID是
5,就在这里填入5。
- 在
-
保存发布设置
- 设置完成后,点击
确定或保存。
- 设置完成后,点击
第五部分:测试与优化
-
测试采集
- 在火车头任务窗口,点击
采集->采集测试。 - 选择
只采集一条,然后点击开始。 - 火车头会抓取一篇文章,并在右侧“采集结果”窗口显示,检查标题、内容、图片链接等是否都正确抓取了。
- 在火车头任务窗口,点击
-
测试发布
- 如果采集测试通过,点击
发布->发布测试。 - 选择
只发布一条,然后点击开始。 - 火车头会尝试将刚刚采集到的内容发布到你的WordPress网站,发布成功后,去你的网站后台检查一下,新文章是否已经创建,内容、图片、分类是否都正确。
- 如果采集测试通过,点击
-
执行采集
- 当测试一切正常后,你就可以放心地执行全量采集了。
- 点击
采集->开始采集,火车头会自动翻页,抓取所有文章。 - 采集完成后,点击
发布->开始发布,将所有采集到的内容发布到你的网站。
重要注意事项与常见问题
- 反爬虫机制:站壳网有反爬虫机制,如果采集时出现大量验证码或IP被屏蔽,你需要:
- 使用代理:在火车头设置中配置代理IP。
- 降低采集频率:在任务设置中增加“延迟时间”,比如每次请求后等待2-5秒。
- 使用User-Agent:设置一个常见的浏览器User-Agent,伪装成真实用户访问。
- 图片路径问题:采集到的图片链接可能是站壳网的绝对路径,在发布时,勾选“下载图片并上传到我的服务器”,火车头会自动下载图片并上传到你的WordPress媒体库,然后替换内容中的链接,这样文章就不会因为对方网站更换图片地址而失效。
- 内容版权:采集他人网站内容时,请务必遵守相关法律法规和网站的版权声明,仅用于个人学习研究,切勿用于商业用途或恶意搬运。
- 规则失效:如果站壳网改版,网页结构发生变化,你之前设置的CSS选择器可能会失效,导致采集失败,这时需要重新分析网站,更新采集规则。
希望这份详细的教程能帮助你成功使用火车头采集站壳网的内容!祝你顺利!


