SQL Server 存储过程终极教程
目录
什么是存储过程?
存储过程(Stored Procedure)是一组为了完成特定功能的 预编译 SQL 语句集合,它被存储在数据库中,可以通过一个名称和指定的参数来调用。
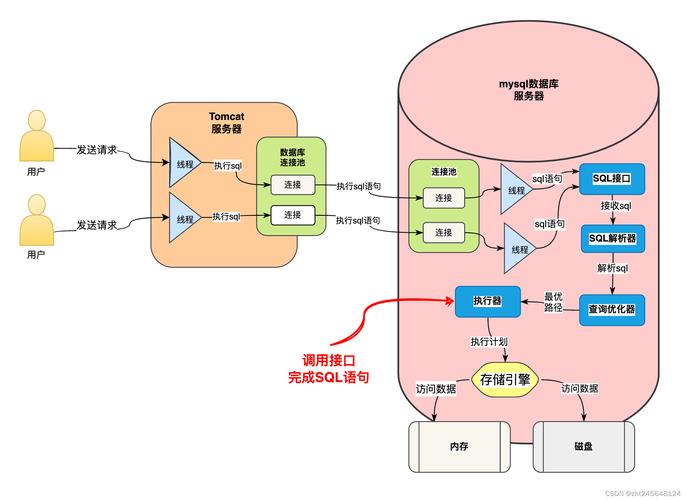
您可以把它想象成一个数据库中的 函数 或 脚本,当您第一次创建存储过程时,SQL Server 会将其编译并存储一个执行计划,之后每次调用它,数据库引擎都会直接重用这个已编译的执行计划,而不是重新解析和优化 SQL 语句,这大大提高了性能。
为什么使用存储过程?
使用存储过程有诸多好处,这也是它在企业级应用中被广泛使用的原因:
- 性能提升:如上所述,存储过程是预编译的,执行计划被缓存,后续调用速度更快。
- 网络流量减少:客户端只需发送一个存储过程名称和参数,而不是一长串复杂的 SQL 语句,从而减少了网络传输的数据量。
- 安全性增强:
- 您可以授予用户执行某个存储过程的权限,而不需要授予他们对底层表的直接访问权限(如
SELECT,INSERT,UPDATE,DELETE)。 - 这实现了“最小权限原则”,有效防止了用户误操作或恶意篡改数据。
- 您可以授予用户执行某个存储过程的权限,而不需要授予他们对底层表的直接访问权限(如
- 代码重用性和一致性:将常用的业务逻辑封装在存储过程中,可以在多个应用程序或模块中重复调用,确保了业务逻辑的统一和标准化。
- 维护性简化:当业务逻辑需要变更时,只需修改存储过程的定义,而不需要修改所有调用它的应用程序代码。
- 减少错误:将复杂的 SQL 逻辑封装在数据库端,可以减少在应用程序代码中编写 SQL 时可能出现的错误。
创建和执行第一个存储过程
让我们从一个最简单的例子开始。
目标:创建一个名为 GetAllEmployees 的存储过程,用于查询 Employees 表中的所有员工信息。

步骤 1: 创建存储过程
使用 CREATE PROCEDURE 或 CREATE PROC 语句。
-- 检查存储过程是否已存在,如果存在则删除,避免重复创建
IF OBJECT_ID('dbo.GetAllEmployees', 'P') IS NOT NULL
DROP PROCEDURE dbo.GetAllEmployees;
GO
-- 创建存储过程
CREATE PROCEDURE dbo.GetAllEmployees
AS
BEGIN
-- 在这里编写您的 SQL 查询
SELECT
EmployeeID,
FirstName,
LastName,
Email,
HireDate
FROM
dbo.Employees;
END
GO
代码解释:
IF OBJECT_ID(...) IS NOT NULL DROP PROCEDURE ...:这是一个好习惯,可以确保每次运行脚本时都是在一个干净的环境下创建新的存储过程,避免因已存在同名过程而报错。CREATE PROCEDURE dbo.GetAllEmployees:声明创建一个名为GetAllEmployees的存储过程,dbo是所有者。AS:关键字,后面是存储过程的主体。BEGIN...END:用于包裹 T-SQL 语句块。SELECT ... FROM dbo.Employees:标准的查询语句。
步骤 2: 执行存储过程
使用 EXECUTE 或 EXEC 关键字来调用存储过程。
EXEC dbo.GetAllEmployees; -- 或者简写为 EXEC GetAllEmployees;
执行后,您将得到 Employees 表的所有数据,就像直接执行那条 SELECT 语句一样。
存储过程的语法详解
存储过程的强大之处在于它能够接收参数、处理逻辑并返回结果。
输入参数
输入参数用于将数据从应用程序传递到存储过程。
示例:创建一个存储过程,根据 DepartmentID 查询员工。
IF OBJECT_ID('dbo.GetEmployeesByDepartment', 'P') IS NOT NULL
DROP PROCEDURE dbo.GetEmployeesByDepartment;
GO
CREATE PROCEDURE dbo.GetEmployeesByDepartment
-- 定义参数,并指定数据类型
@DepartmentID INT
AS
BEGIN
SELECT
EmployeeID,
FirstName,
LastName
FROM
dbo.Employees
WHERE
DepartmentID = @DepartmentID;
END
GO
执行:
-- 查询部门ID为 3 的所有员工 EXEC dbo.GetEmployeesByDepartment @DepartmentID = 3; -- 或者使用参数位置(不推荐,因为当参数顺序改变时会出错) EXEC dbo.GetEmployeesByDepartment 3;
输出参数
输出参数用于将数据从存储过程返回给调用者。
示例:创建一个存储过程,计算指定部门的员工人数,并将结果通过输出参数返回。
IF OBJECT_ID('dbo.GetEmployeeCountByDepartment', 'P') IS NOT NULL
DROP PROCEDURE dbo.GetEmployeeCountByDepartment;
GO
CREATE PROCEDURE dbo.GetEmployeeCountByDepartment
@DepartmentID INT,
-- 定义输出参数,使用 OUTPUT 关键字
@EmployeeCount INT OUTPUT
AS
BEGIN
SELECT @EmployeeCount = COUNT(*)
FROM
dbo.Employees
WHERE
DepartmentID = @DepartmentID;
END
GO
执行:
调用带输出参数的存储过程时,必须声明一个变量来接收返回值,并在调用时使用 OUTPUT 关键字。
-- 1. 声明一个变量来接收输出参数
DECLARE @Count INT;
-- 2. 执行存储过程,并传入输出变量
EXEC dbo.GetEmployeeCountByDepartment
@DepartmentID = 3,
@EmployeeCount = @Count OUTPUT;
-- 3. 打印结果
PRINT '部门 3 的员工人数是: ' + CAST(@Count AS VARCHAR(10));
返回值
存储过程可以通过 RETURN 语句返回一个整数值,通常用于表示操作的成功或失败状态(0 表示成功,-1 表示失败)。
示例:修改上面的存储过程,如果部门不存在,则返回 -1。
IF OBJECT_ID('dbo.GetEmployeeCountByDepartmentWithReturn', 'P') IS NOT NULL
DROP PROCEDURE dbo.GetEmployeeCountByDepartmentWithReturn;
GO
CREATE PROCEDURE dbo.GetEmployeeCountByDepartmentWithReturn
@DepartmentID INT,
@EmployeeCount INT OUTPUT
AS
BEGIN
-- 检查部门是否存在
IF NOT EXISTS (SELECT 1 FROM dbo.Departments WHERE DepartmentID = @DepartmentID)
BEGIN
-- 返回 -1 表示部门不存在
RETURN -1;
END
SELECT @EmployeeCount = COUNT(*)
FROM dbo.Employees
WHERE DepartmentID = @DepartmentID;
-- 返回 0 表示成功
RETURN 0;
END
GO
执行:
DECLARE @Count INT;
DECLARE @ReturnValue INT;
-- 执行存储过程并捕获返回值
EXEC @ReturnValue = dbo.GetEmployeeCountByDepartmentWithReturn
@DepartmentID = 99, -- 假设这个部门不存在
@EmployeeCount = @Count OUTPUT;
IF @ReturnValue = 0
PRINT '操作成功,员工人数: ' + CAST(@Count AS VARCHAR(10));
ELSE IF @ReturnValue = -1
PRINT '错误:指定的部门不存在!';
局部变量
局部变量在存储过程内部声明和使用,通常用于存储中间计算结果或查询结果。
- 声明:
DECLARE @VariableName DataType; - 赋值:
SET @VariableName = Value;或SELECT @VariableName = ColumnName FROM ...;
CREATE PROCEDURE dbo.GetEmployeeDetails
@EmployeeID INT
AS
BEGIN
DECLARE @EmployeeName NVARCHAR(100);
DECLARE @HireDate DATE;
-- 将查询结果赋值给变量
SELECT
@EmployeeName = FirstName + ' ' + LastName,
@HireDate = HireDate
FROM
dbo.Employees
WHERE
EmployeeID = @EmployeeID;
-- 使用变量
IF @EmployeeName IS NOT NULL
BEGIN
PRINT '员工 ' + @EmployeeName + ' 的入职日期是: ' + CONVERT(VARCHAR, @HireDate, 120);
END
ELSE
BEGIN
PRINT '未找到ID为 ' + CAST(@EmployeeID AS VARCHAR(10)) + ' 的员工。';
END
END
GO
流程控制
T-SQL 提供了类似其他编程语言的流程控制语句,如 IF...ELSE, WHILE, CASE 等。
示例:使用 CASE 语句根据员工职位返回不同的薪资等级。
CREATE PROCEDURE dbo.GetEmployeeSalaryGrade
@EmployeeID INT
AS
BEGIN
SELECT
FirstName,
LastName,
JobTitle,
Salary,
CASE
WHEN Salary > 100000 THEN 'A'
WHEN Salary > 70000 THEN 'B'
ELSE 'C'
END AS SalaryGrade
FROM
dbo.Employees
WHERE
EmployeeID = @EmployeeID;
END
GO
高级主题
使用 TRY...CATCH 处理错误
与高级语言类似,T-SQL 也有异常处理机制。TRY...CATCH 块可以捕获运行时错误,使您的存储过程更加健壮。
ERROR_NUMBER(): 返回错误号。ERROR_MESSAGE(): 返回错误消息。ERROR_SEVERITY(): 返回错误严重性。ERROR_STATE(): 返回错误状态。
示例:
CREATE PROCEDURE dbo.InsertEmployeeWithValidation
@FirstName NVARCHAR(50),
@LastName NVARCHAR(50),
@Email NVARCHAR(100),
@DepartmentID INT
AS
BEGIN
BEGIN TRY
-- 检查部门是否存在
IF NOT EXISTS (SELECT 1 FROM dbo.Departments WHERE DepartmentID = @DepartmentID)
BEGIN
-- 抛出一个自定义错误,将被 CATCH 块捕获
RAISERROR('部门ID %d 不存在。', 16, 1, @DepartmentID);
RETURN; -- 直接退出
END
-- 插入员工
INSERT INTO dbo.Employees (FirstName, LastName, Email, DepartmentID)
VALUES (@FirstName, @LastName, @Email, @DepartmentID);
PRINT '员工 ' + @FirstName + ' ' + @LastName + ' 插入成功!';
END TRY
BEGIN CATCH
PRINT '插入员工时发生错误: ';
PRINT '错误号: ' + CAST(ERROR_NUMBER() AS VARCHAR(10));
PRINT '错误信息: ' + ERROR_MESSAGE();
END CATCH
END
GO
带事务的存储过程
事务确保一组操作要么全部成功,要么全部失败,以维护数据的一致性。
BEGIN TRANSACTION: 开始一个事务。COMMIT TRANSACTION: 提交事务,使更改永久化。ROLLBACK TRANSACTION: 回滚事务,撤销所有更改。
示例:从一个账户转账到另一个账户。
CREATE PROCEDURE dbo.TransferFunds
@FromAccountID INT,
@ToAccountID INT,
@Amount DECIMAL(18, 2)
AS
BEGIN
BEGIN TRANSACTION;
BEGIN TRY
-- 扣除FromAccount的金额
UPDATE dbo.Accounts
SET Balance = Balance - @Amount
WHERE AccountID = @FromAccountID AND Balance >= @Amount;
-- 检查是否成功扣除
IF @@ROWCOUNT = 0
BEGIN
-- 余额不足,抛出错误
RAISERROR('转账失败:账户余额不足。', 16, 1);
END
-- 增加ToAccount的金额
UPDATE dbo.Accounts
SET Balance = Balance + @Amount
WHERE AccountID = @ToAccountID;
-- 如果所有操作都成功,则提交事务
COMMIT TRANSACTION;
PRINT '转账成功!';
END TRY
BEGIN CATCH
-- 如果发生任何错误,则回滚事务
IF @@TRANCOUNT > 0
ROLLBACK TRANSACTION;
PRINT '转账失败,事务已回滚。';
PRINT '错误信息: ' + ERROR_MESSAGE();
END CATCH
END
GO
使用游标
游标是一种数据库对象,它允许您逐行处理查询结果集。游标会降低性能,应谨慎使用,通常在没有其他更好方法时(如使用 WHILE 循环处理复杂逻辑)才使用。
示例:为所有员工的薪资增加 5%。
CREATE PROCEDURE dbo.GiveRaiseToAllEmployees
AS
BEGIN
-- 声明变量
DECLARE @EmployeeID INT;
DECLARE @CurrentSalary DECIMAL(18, 2);
DECLARE @NewSalary DECIMAL(18, 2);
-- 声明游标
DECLARE EmployeeCursor CURSOR FOR
SELECT EmployeeID, Salary FROM dbo.Employees;
-- 打开游标
OPEN EmployeeCursor;
-- 获取第一行数据
FETCH NEXT FROM EmployeeCursor INTO @EmployeeID, @CurrentSalary;
-- 循环处理每一行
WHILE @@FETCH_STATUS = 0
BEGIN
-- 计算新薪资
SET @NewSalary = @CurrentSalary * 1.05;
-- 更新薪资
UPDATE dbo.Employees
SET Salary = @NewSalary
WHERE EmployeeID = @EmployeeID;
-- 获取下一行数据
FETCH NEXT FROM EmployeeCursor INTO @EmployeeID, @CurrentSalary;
END
-- 关闭并释放游标
CLOSE EmployeeCursor;
DEALLOCATE EmployeeCursor;
PRINT '所有员工薪资已更新。';
END
GO
返回结果集
除了使用输出参数返回单个值,存储过程最常见的用法是直接返回一个结果集(就像 SELECT 语句一样),这在分页、报表等场景中非常有用。
-- 这个存储过程返回一个复杂的结果集
CREATE PROCEDURE dbo.GetEmployeeDepartmentReport
AS
BEGIN
SELECT
e.EmployeeID,
e.FirstName + ' ' + e.LastName AS FullName,
e.Email,
d.DepartmentName,
d.ManagerName
FROM
dbo.Employees e
INNER JOIN
dbo.Departments d ON e.DepartmentID = d.DepartmentID
ORDER BY
d.DepartmentName, e.LastName;
END
GO
-- 执行它,你会得到一个表格形式的结果
EXEC dbo.GetEmployeeDepartmentReport;
管理存储过程
-
查看存储过程定义:
-- 使用 sp_helptext EXEC sp_helptext 'dbo.GetAllEmployees'; -- 或者查询系统视图 SELECT definition FROM sys.sql_modules WHERE object_id = OBJECT_ID('dbo.GetAllEmployees'); -
查看存储过程依赖:
EXEC sp_depends 'dbo.GetAllEmployees'; -- 或者查询系统视图 SELECT referenced_id, referenced_class_desc, referenced_minor_name FROM sys.sql_expression_dependencies WHERE referencing_id = OBJECT_ID('dbo.GetAllEmployees'); -
修改存储过程: 使用
ALTER PROCEDURE,这会替换存储过程的定义,但不会改变其权限。ALTER PROCEDURE dbo.GetAllEmployees AS BEGIN -- 修改后的逻辑 SELECT TOP 10 EmployeeID, FirstName FROM dbo.Employees ORDER BY HireDate DESC; END GO -
删除存储过程:
DROP PROCEDURE dbo.GetAllEmployees; GO
最佳实践
- 使用
SET NOCOUNT ON:在存储过程开头加上SET NOCOUNT ON;,可以防止向客户端返回受INSERT,UPDATE,DELETE语句影响的行数信息,减少网络流量。 - 参数化查询:始终使用参数来传递值,而不是直接将值拼接到 SQL 字符串中,以防止 SQL 注入 攻击。
- 合理的错误处理:对于关键业务逻辑,始终使用
TRY...CATCH和事务来保证数据一致性。 - 清晰的命名:为存储过程、参数和变量使用有意义的、一致的命名规范(使用
sp_前缀通常保留给系统存储过程,建议使用自定义前缀如usp_或直接使用模块名)。 - 注释:为复杂的逻辑添加注释,方便自己和他人日后维护。
- 谨慎使用游标:优先使用基于集合的操作(如
JOIN,GROUP BY),它们通常比游标快得多。 - 限制权限:只授予用户执行特定存储过程的权限,而不是直接访问表的权限。
存储过程是 SQL Server 数据库编程中不可或缺的强大工具,它通过将业务逻辑封装在数据库层,极大地提升了应用程序的性能、安全性和可维护性。
本教程涵盖了从创建、执行到使用参数、错误处理、事务等核心概念,希望这份指南能帮助您从入门到精通,在您的项目中熟练运用存储过程,最好的学习方式就是 动手实践,尝试用存储过程来解决您日常工作中遇到的实际问题。


