核心实现思路
实现 UBB 标签主要有两种方法:

(图片来源网络,侵删)
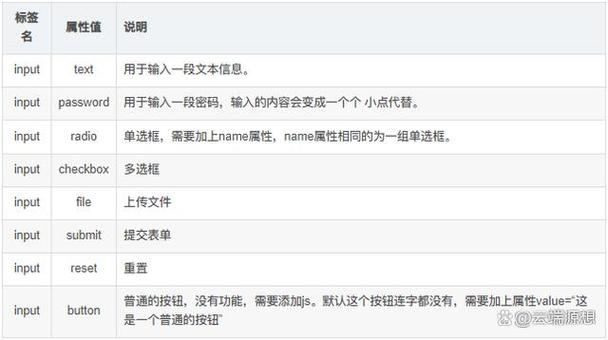
- 字符串替换法:使用 PHP 的
str_replace()或preg_replace()函数,将 UBB 标签一对一地替换成对应的 HTML 标签,这种方法简单直接,适合处理少量、固定的标签。 - 正则表达式法:使用更强大的正则表达式 (
preg_replace()),可以处理更复杂的嵌套和带属性的标签(如[url=http://example.com]链接[/url]),这是最常用和推荐的方法。
我们将重点介绍第二种方法,因为它更灵活、更强大。
第一步:准备一个简单的 HTML 表单
我们需要一个让用户输入内容的界面,创建一个 index.php 文件。
<!DOCTYPE html>
<html lang="zh-CN">
<head>
<meta charset="UTF-8">PHP UBB 标签演示</title>
<style>
body { font-family: sans-serif; line-height: 1.6; margin: 2em; }
textarea { width: 100%; height: 150px; padding: 10px; }
input[type="submit"] { padding: 10px 20px; }
.ubb-preview { margin-top: 20px; padding: 15px; border: 1px solid #ccc; background-color: #f9f9f9; }
</style>
</head>
<body>
<h1>PHP UBB 标签演示</h1>
<p>请输入包含 UBB 标签的文本,<code>[b]粗体[/b]</code>, <code>[i]斜体[/i]</code>, <code>[url=http://www.php.net]PHP官网[/url]</code></p>
<form action="process.php" method="post">
<textarea name="ubb_content" placeholder="在这里输入你的内容..."><?php echo isset($_POST['ubb_content']) ? htmlspecialchars($_POST['ubb_content']) : ''; ?></textarea>
<br><br>
<input type="submit" value="提交并预览">
</form>
<?php if (isset($_POST['ubb_content']) && !empty($_POST['ubb_content'])): ?>
<div class="ubb-preview">
<h3>预览效果:</h3>
<div>
<?php
// 在这里我们将引入处理逻辑
require_once 'ubb_parser.php';
$html_output = parse_ubb($_POST['ubb_content']);
echo $html_output;
?>
</div>
</div>
<?php endif; ?>
</body>
</html>
第二步:创建 UBB 解析器 (ubb_parser.php)
这是核心部分,我们将创建一个单独的文件 ubb_parser.php,用于存放所有转换逻辑,使用正则表达式,我们可以非常优雅地完成这个任务。
<?php
/**
* 将 UBB 标签转换为 HTML 标签
* @param string $ubb_text 包含 UBB 标签的文本
* @return string 转换后的 HTML 文本
*/
function parse_ubb($ubb_text) {
// 1. 安全处理:防止 XSS 攻击
// 在转换前,先将所有尖括号等特殊字符转义
$safe_text = htmlspecialchars($ubb_text, ENT_QUOTES, 'UTF-8');
// 2. 定义 UBB 标签的正则表达式替换规则
// 数组的键是正则表达式,值是替换成的 HTML 字符串
$ubb_patterns = [
// [b]粗体[/b]
'/\[b\](.*?)\[\/b\]/is' => '<b>$1</b>',
// [i]斜体[/i]
'/\[i\](.*?)\[\/i\]/is' => '<i>$1</i>',
// [u]下划线[/u]
'/\[u\](.*?)\[\/u\]/is' => '<u>$1</u>',
// [size=大小]文本[/size]
'/\[size=([1-7])\](.*?)\[\/size\]/is' => '<font size="$1">$2</font>', // HTML5已废弃,但为了演示
// 更现代的方式是使用 CSS
'/\[size=(\d+)px\](.*?)\[\/size\]/is' => '<span style="font-size: $1px">$2</span>',
// [color=颜色]文本[/color]
'/\[color=([a-zA-Z0-9#]+)\](.*?)\[\/color\]/is' => '<span style="color: $1">$2</span>',
// [align=对齐方式]文本[/align]
'/\[align=(left|center|right|justify)\](.*?)\[\/align\]/is' => '<div style="text-align: $1">$2</div>',
// [list]列表项[*]列表项[/list]
'/\[list\](.*?)\[\/list\]/is' => '<ul>$1</ul>',
'/\[\*\](.*?)(?=\[\*\]|\[\/list\]|\z)/is' => '<li>$1</li>',
// [url]链接[/url]
'/\[url\](.*?)\[\/url\]/is' => '<a href="$1" target="_blank">$1</a>',
// [url=链接地址]显示文字[/url]
'/\[url=(.*?)\](.*?)\[\/url\]/is' => '<a href="$1" target="_blank">$2</a>',
// [img]图片地址[/img]
'/\[img\](.*?)\[\/img\]/is' => '<img src="$1" alt="用户图片" style="max-width: 100%; height: auto;">',
// [email]邮箱地址[/email]
'/\[email\](.*?)\[\/email\]/is' => '<a href="mailto:$1">$1</a>',
// [quote]引用内容[/quote]
'/\[quote\](.*?)\[\/quote\]/is' => '<blockquote style="border-left: 2px solid #ccc; padding-left: 10px; margin-left: 10px;">$1</blockquote>',
// [code]代码[/code]
'/\[code\](.*?)\[\/code\]/is' => '<pre style="background-color: #f0f0f0; padding: 10px; border-radius: 4px;"><code>$1</code></pre>',
];
// 3. 执行替换
// 使用 preg_replace_callback 可以实现更复杂的逻辑,但这里用 preg_replace 足够
$html_text = preg_replace(array_keys($ubb_patterns), array_values($ubb_patterns), $safe_text);
// 4. 处理换行
// 将 UBB 的换行符 [br] 或单换行转换为 HTML 的 <br> 标签
$html_text = str_replace("[br]", "<br>", $html_text);
$html_text = nl2br($html_text); // 将 \n 转换为 <br>
return $html_text;
}
?>
代码解释:
(图片来源网络,侵删)
htmlspecialchars(): 这是至关重要的安全步骤,它将<,>,&, , 等字符转换为 HTML 实体,这样做可以防止用户输入<script>alert('xss')</script>这样的恶意脚本被执行,有效防止 XSS (跨站脚本) 攻击。- 正则表达式
/.../is:- 是定界符。
i: 表示 不区分大小写 (case-insensitive)。[b]和[B]都能被匹配。s: 表示 单行模式 (single-line),它使得 (点号) 也能匹配换行符,这对于处理[b]多行文本[/b]这样的情况非常重要。
- *`/(.?)[/tag]/is`**:
\[和\]: 因为[和]在正则表达式中有特殊含义,所以需要用\转义。- 这是一个非贪婪匹配的捕获组。 匹配任意字符, 表示匹配 0 次或多次, 使其变为非贪婪模式,即匹配到第一个
[/tag]就停止,而不是最后一个,这对于处理嵌套标签(虽然 UBB 通常不鼓励嵌套)或多重标签非常关键。 $1: 这是一个反向引用,代表第一个捕获组 匹配到的内容。
preg_replace(): 它接受一个模式数组和一个对应的替换字符串数组,然后一次性执行所有替换,效率很高。nl2br(): 这是一个很方便的 PHP 函数,它会把字符串中的换行符\n转换成 HTML 的<br>标签,让文本段落更清晰。
第三步:安全性与优化(非常重要!)
上面的基本实现已经可以工作,但在生产环境中,你还必须考虑以下几点:
严格的安全过滤(防XSS)
我们已经在解析前使用了 htmlspecialchars(),这是第一道防线,但为了更彻底的安全,特别是当内容要存储到数据库时,应该在写入数据库前也进行一次转义。
// 假设你使用 MySQLi $ubb_content_from_post = $_POST['ubb_content']; $escaped_content = mysqli_real_escape_string($your_db_connection, $ubb_content_from_post); // 然后将 $escaped_content 存入数据库
处理嵌套标签
标准的 UBB 解析器通常不支持嵌套,[b][i]粗斜体[/i][/b],上面的正则表达式会错误地处理它。
解决方案:递归解析
(图片来源网络,侵删)
可以创建一个递归函数来处理嵌套。
// 在 ubb_parser.php 中修改 parse_ubb 函数
function parse_ubb_recursive($text) {
// ... (定义 $ubb_patterns 数组,和之前一样) ...
$count = 0;
$new_text = preg_replace(array_keys($ubb_patterns), array_values($ubb_patterns), $text, -1, $count);
// 如果本次替换发生了,说明可能还有嵌套的标签,需要再次解析
if ($count > 0) {
return parse_ubb_recursive($new_text);
}
return $new_text;
}
// 主解析函数
function parse_ubb($ubb_text) {
$safe_text = htmlspecialchars($ubb_text, ENT_QUOTES, 'UTF-8');
$html_text = parse_ubb_recursive($safe_text);
$html_text = str_replace("[br]", "<br>", $html_text);
$html_text = nl2br($html_text);
return $html_text;
}
这个递归函数会一直解析,直到文本中不再有任何 UBB 标签被替换为止,从而正确处理嵌套。
性能考虑
非常长,或者 UBB 标签非常复杂,大量的正则表达式替换可能会影响性能。
- 缓存: 如果内容不经常变化(比如帖子发布后),可以将解析后的 HTML 缓存起来(例如存入数据库的一个新字段
html_content,或者使用 Redis、Memcached 等内存缓存),这样下次直接读取缓存即可,无需重复解析。 - 简化正则: 尽量使用高效、简单的正则表达式,避免使用过于复杂的回溯模式。
总结与最终代码结构
index.php: 负责展示表单和预览结果。ubb_parser.php: 包含parse_ubb()核心函数,负责所有转换逻辑。
index.php (最终版)
<?php
require_once 'ubb_parser.php';
?>
<!DOCTYPE html>
<html lang="zh-CN">
<head>
<meta charset="UTF-8">PHP UBB 标签演示</title>
<style>
/* ... (CSS 保持不变) ... */
</style>
</head>
<body>
<h1>PHP UBB 标签演示</h1>
<p>请输入包含 UBB 标签的文本,<code>[b]粗体[/b]</code>, <code>[i]斜体[/i]</code>, <code>[url=http://www.php.net]PHP官网[/url]</code></p>
<form action="index.php" method="post"> <!-- 改为提交给自己 -->
<textarea name="ubb_content" placeholder="在这里输入你的内容..."><?php echo isset($_POST['ubb_content']) ? htmlspecialchars($_POST['ubb_content'], ENT_QUOTES, 'UTF-8') : ''; ?></textarea>
<br><br>
<input type="submit" value="提交并预览">
</form>
<?php if ($_SERVER['REQUEST_METHOD'] === 'POST' && isset($_POST['ubb_content']) && !empty(trim($_POST['ubb_content']))): ?>
<div class="ubb-preview">
<h3>预览效果:</h3>
<div>
<?php
// 直接调用解析函数并输出
echo parse_ubb($_POST['ubb_content']);
?>
</div>
</div>
<?php endif; ?>
</body>
</html>
ubb_parser.php (最终版,包含递归)
<?php
/**
* 将 UBB 标签转换为 HTML 标签 (递归版本)
* @param string $ubb_text 包含 UBB 标签的文本
* @return string 转换后的 HTML 文本
*/
function parse_ubb($ubb_text) {
// 1. 安全处理:防止 XSS 攻击
$safe_text = htmlspecialchars($ubb_text, ENT_QUOTES, 'UTF-8');
// 2. 定义 UBB 标签的正则表达式替换规则
$ubb_patterns = [
'/\[b\](.*?)\[\/b\]/is' => '<strong>$1</strong>', // <strong> 是语义化更好的选择
'/\[i\](.*?)\[\/i\]/is' => '<em>$1</em>', // <em> 是语义化更好的选择
'/\[u\](.*?)\[\/u\]/is' => '<u>$1</u>',
'/\[size=(\d+)px\](.*?)\[\/size\]/is' => '<span style="font-size: $1px;">$2</span>',
'/\[color=([a-zA-Z0-9#]+)\](.*?)\[\/color\]/is' => '<span style="color: $1;">$2</span>',
'/\[align=(left|center|right|justify)\](.*?)\[\/align\]/is' => '<div style="text-align: $1;">$2</div>',
'/\[list\](.*?)\[\/list\]/is' => '<ul>$1</ul>',
'/\[\*\](.*?)(?=\[\*\]|\[\/list\]|\z)/is' => '<li>$1</li>',
'/\[url\](.*?)\[\/url\]/is' => '<a href="$1" target="_blank" rel="noopener noreferrer">$1</a>',
'/\[url=(.*?)\](.*?)\[\/url\]/is' => '<a href="$1" target="_blank" rel="noopener noreferrer">$2</a>',
'/\[img\](.*?)\[\/img\]/is' => '<img src="$1" alt="用户图片" style="max-width: 100%; height: auto;" loading="lazy">',
'/\[email\](.*?)\[\/email\]/is' => '<a href="mailto:$1">$1</a>',
'/\[quote\](.*?)\[\/quote\]/is' => '<blockquote style="border-left: 3px solid #ccc; padding-left: 15px; margin-left: 0;">$1</blockquote>',
'/\[code\](.*?)\[\/code\]/is' => '<pre style="background-color: #f4f4f4; padding: 10px; border-radius: 4px; overflow-x: auto;"><code>$1</code></pre>',
];
// 3. 执行递归替换
$html_text = parse_ubb_recursive($safe_text, $ubb_patterns);
// 4. 处理换行
$html_text = str_replace("[br]", "<br>", $html_text);
// 只有在需要时才使用 nl2br,因为它会把每个 \n 都变成 <br>
// 如果你的编辑器是 WYSIWYG 类型,可能不需要这一步
if (strpos($html_text, "\n") !== false) {
$html_text = nl2br($html_text);
}
return $html_text;
}
/**
* 递归解析 UBB 标签的辅助函数
* @param string $text
* @param array $patterns
* @return string
*/
function parse_ubb_recursive($text, $patterns) {
$count = 0;
$new_text = preg_replace(array_keys($patterns), array_values($patterns), $text, -1, $count);
if ($count > 0) {
return parse_ubb_recursive($new_text, $patterns);
}
return $new_text;
}
?>
通过以上步骤,你就拥有了一个功能相对完善、安全性较高的 PHP UBB 标签解析器,你可以根据需要,在 $ubb_patterns 数组中轻松地添加或修改更多的标签规则。


